中国人民大学统计学院、教育部应用统计科学研究中心
为借鉴发达国家经验,加强国际统计学者之间的相互交流, 促进中国统计事业的发展,推动中国统计科学研究与国际水平接轨,第四届中国人民大学国际统计论坛暨第五届统计科学前沿国际研讨会于2010年7月10日-12日在中国人民大学举行。论坛由中国人民大学统计学院、应用统计研究中心、中国科学院数学与系统科学研究院、北京大学统计科学中心、国家统计局统计科学研究所等单位联合主办,首都经贸大学、中央财经大学、对外经济贸易大学、中国科学院随机复杂结构和数据科学重点实验室、西安财经学院协办。
本届论坛规模和水平空前,受到了国家领导人和相关部门领导的高度重视,得到了国内众多所高校和研究机构的支持。7月10日上午,全国人大常委会副委员长陈昌智、教育部副部长郝平、国家统计局局长马建堂、中国人民大学党委书记程天权教授、常务副校长袁卫教授和普林斯顿大学范剑青教授出席了本届论坛开幕式并致辞。陈昌智说到,社会的不断进步,统计对于社会的作用日益增大;加快建立适应科学发展需要的现代统计体系,让我们的政府统计发挥更大的作用,便成为当前我国统计事业发展的一个重要挑战。他强调,我国经济社会的快速发展和统计工作的丰富实践,为统计科学的发展提供着充足的营养,统计科研人员要大胆“引进来”、“走出去”,与各国统计界进行深度交流,共同推动统计科学事业的发展。郝平表示,本届国际统计论坛成功举办必将推动中国人民大学乃至国内高校和科研机构统计研究水平的提高,他相信此次论坛会成为为中国统计学界迈向国际统计研究前沿的更为坚定的一步。马建堂代表国家统计局向本届论坛和统计事业的发展表示祝愿,他指出中国统计工作有全球的优势,但也面临挑战,是开展统计科研与教学培养人才的肥沃土壤,政府统计工作倡导科学研究的重要基础作用,以科研不断创新推动统计实际工作的不断改革与发展,他也对统计专业的大学生和研究生寄予厚望,祝愿他们在中国统计事业最重要的发展阶段,能够发挥更大的作用和做出更大的贡献。程天权书记对人民大学统计学科的建设与发展做出了高度评价,也代表人大全体师生向来宾表示热烈的欢迎。
在为期两天半的会议期间,共有9名来自美国、澳大利亚和中国的具有统计学背景的科学院院士,多名考普斯奖(美国四大统计学会会长年度奖)获得者,以及斯坦福大学、哈佛大学、加州大学、耶鲁大学、中国人民大学、北京大学、中国科学院等院校的统计学者约500多人参加会议,在9位院士特邀报告和63个分会场共299篇统计学的前沿研究成果进行了学术交流。主要内容综述如下。
一、统计学科发展方向的院士特邀研究报告
1、基因图谱的统计方法研究
论坛特邀院士报告中有三位美国院士所做研究报告是基因图谱的统计方法研究,可见这个方向在美国的重要性。大卫西格蒙德(David O. Siegmund,美国科学院院士,斯坦福大学统计学教授),目前主要集中在基因图谱的统计方法研究。他高兴地介绍,基因图谱的主要作用是确定那些与人类健康有关系的基因,这些基因可以是致病基因,也可以是控制人类体貌特征的基因,比如高度,头发颜色等。当我们的研究真正找到了致病的基因,比如说癌症的基因,那么就可以通过适当的生物技术改变他们,挽救癌症患者的生命。比如,我们可以提前诊断出婴儿是否携带某些严重的致病基因,以便及早寻求保障健康的办法。大卫肯定地表示,基因图谱的研究是一项可以为子孙后代带来福祉的工程,但基因图谱的研究是一个长期工程,不像在银行存钱,今天存了,明天就可以拿到利息。
大卫 西格蒙德所做的研究报告是“多个序列中同时变点的探测”,他的主要研究是在DNA的多序列里探查同时发生的点改变。针对原先的研究都是基于对DNA单个序列的独立分析进行的,David在演讲中提出了新的统计方法可以联合多个序列的数据进行分析,这样能获得更好的检验效力,而且能更好的对数据进行解释。这个统计模型的提出也是为了解决在多个样本里探查DNA拷贝数目变异的问题,他的研究结果可以很好的运用到这其中。
米切尔 瓦特曼(Michael S. Waterman,美国科学院院士,美国南加州大学生物学、数学、计算机科学教授)所做的研究报告是“循着欧拉路径来读懂DNA序列”,他在回顾和总结DNA序列分析的历史基础上,系统讨论了有关DNA序列拼接研究进展与挑战,他的主要研究是探讨新时期DNA序列研究特点以及应用欧拉图方法对DNA序列进行分析的优势与难点。
彼得 比克尔(Peter Bickel,美国科学院院士,加州大学伯克利分校统计系教授)所做的研究报告是“基因学中的统计推断实例”,他介绍了他们所参与的ENCODE(DNA的百科全书)分析工作小组的两个问题。这个小组是一个致力于标记人类基因组功能的国际合作组织,他们的问题已经由该组织以及其他人实现和利用。主要研究成果是:(1)评价何时两个基因特性是相互独立的。(2)评价用于寻迹的peak callers以及利用生物重复信号变得嘈杂的点的可靠性。
2、概率统计理论的应用前沿
随着学科间的交叉融合和统计研究领域的拓展,概率统计理论的应用在不断深化,论坛特邀院士报告中有两位院士利用概率统计理论做了相关开拓性研究。王永雄(Wing Hung Wong,美国科学院院士,斯坦福大学统计系主任、教授)将概率统计理论与机器学习进行了深度融合,为机器学习与概率统计学科群的开辟提供了基础平台。为了提高搜索引擎算法的效率,马志明(中国科学院院士,中国数学会理事长)引入概率统计的思想,提出了BrowseRank搜索引擎算法,有效的改进了传统的PageRank搜索引擎算法的不足。
王永雄(Wing Hung Wong,美国科学院院士,斯坦福大学统计系主任、教授)所做的研究报告是 “可选波亚树与贝叶斯推断”,他提出使用推广的Polya树方法构造概率测度空间,强调在异质性环境中测度空间、变量选择和统计推断设计三者之间关系的复杂性和重要性。探讨替代停止和替代选择拆分变量机制,讨论了使用新机制构造的随机测度的优点,主要的结论是空间分割的分段光滑密度绝对连续,可以保障在全变差拓扑空间上有较大的非零域,产生的后验分布还是替代Polya树,为高维离散和连续的多元分布的概率空间构造提供了机器学习理论。该报告在概率空间学研究方面具有非常重要的引导作用,将为机器学习与概率统计学科群的开辟提供基础平台。
马志明(中国科学院院士,中国数学会理事长)所做的研究报告是“由网络信息检索引发的概率与统计问题”。报告是马志明院士领导的一个研究团队所进行的研究工作和研究成果。报告首先阐述了网络搜索引擎的一些重要进展,特别是PageRank的发展情况,其中着重介绍了报告人本人所带领的研究团队在PageRank算法方面的一些研究成果,包括PageRank的极限,不同不可约马氏链的比较,N-步PageRank等。此外针对PageRank的一些弱点,报告中详细介绍了其研究团队所提出的另外一个搜索引擎:BrowseRank,包括此算法的原理,计算方法,数据分析等。在报告的后半部分,介绍了因特网信息检索也即搜索引擎的算法设计和分析过程中所涉及的主要概率和统计问题,包括浏览过程和 two-layer 统计学习等。重点介绍了其研究团队的研究成果,包括他们所提出的一种新型的马尔科夫骨架过程以及基于此过程提出了一种给网页重要性排序的算法,two-layer 统计学习及其在网络检索中的应用等。最后报告提出了一些未来可以研究的问题以及可能遇到的挑战。
马志明院士研究指出,由于Inter网的广泛使用,对网上信息的检索每天都在大量的发生,如何提高搜索引擎算法的效率就是一个非常重要的问题,而对这方面的研究也是当前非常活跃的研究领域。人们在浏览网页,检索信息的过程中随机性的存在是很显然的,如果在搜索引擎的算法设计中,考虑到这些随机性,给出其合理的描述,则会对搜索算法的改进有很大的帮助。而如何描述这些随机性,将概率统计的思想和方法合理地引入和应用于此问题,就是一个非常有意义的研究方向。报告人及其所带领的研究团队除了利用已有的概率统计方法研究了经典的PageRank算法外,更重要的是他们深入分析了人们在网上浏览、检索信息的行为,引入了概率统计的思想和方法,提出了一种新的搜索算法:BrowseRank,这一算法已经引起了人们的关注。此外,他们给出了人们在网上浏览、检索信息行为的随机模型:一种新的马尔科夫骨架过程,并基于此提出了给网页重要性排序的算法。他们还将统计学习的思想方法引入到搜索算法的研究中,提出了two-layer 统计学习方法。从这个报告中可以得到的结论是:概率统计的理论和方法在搜索引擎算法的研究中将会起到越来越重要的作用,而反过来,对网络信息检索的研究也为概率统计提供了越来越多的有趣和有挑战性的问题。
3、经典统计方法研究的新动向
随着经济社会的不断发展,社会各界对统计分析的需求与日俱增,统计方法有着更为广袤的应用前景。但是,学者们逐渐发现经典统计方法中的相关假设、适用范围等难以满足现实分析中的要求,对经典统计方法的拓展研究成为统计研究中的一大主题,论坛特邀院士报告中有两位院士分别对聚类分析方法和纵向数据模型进行了新的探讨。
彼得 G. 霍尔(Peter G. Hall,澳大利亚科学院院士,澳大利亚墨尔本大学数学与统计系教授)所做的研究报告是“多模态证据运用下的密集高维数据”。Hall 在他的报告中指出,绝大多数“非参数”多元数据聚类方法都是基于归类和分类方法,采用的是距离测度或相异性度量。Hastie 等人(2009) 讨论并比较了不同的方法。例如K-均值聚类法是基于数据向量间的欧氏平方距离进行比较的,并进行聚类使到类中心距离最小。然而,当维度相对于样本大小来说非常高时,就有可能使得许多成分包含的信息与噪声无差别。那样的话,通过度量欧式距离对每个成份相同的处理,可以导致许多噪声成分,这些噪音成分隐藏了聚类的重要信息,而这些信息其实可以在数目小得多的其他一些成分中得到。这些考虑激发了我们在利用一个聚类方法之前去考虑变量或特征的显著性选择问题。然而,大量的高维数据的变量选择器强调的是响应变量Y与解释变量X是一起测量的。该报告所讨论的只是解释变量具有观测值。他对方法的发展进行了系统的讨论,指出基于对多峰性的非参数检验问题的聚类方法有很多优势,相对于其他方法,它很容易解释并且不受参数模型当中拟合优度的影响。模拟研究表明基于超大量检验的聚类方法是相对稳定的,对于边际分布是非齐性来讲,如果成分是相互依赖的情况,如果潜在的分布是厚尾情况或显著的成分数量很少的情况下,该方法对比其他据类方法来说表现优越。另一方面,基于超大量检验的据类方法可能胜过其他方法,例如k均值聚类法,EI方法,在许多成分需要有效聚类的情况下。针对这一性质,当k均值聚类和EI方法不能大量的推进或降低时,当选择成分的数量q不同时,超大量方法对于小q表现很好,但是对于大q表现较差,这是正常的,因为变量选择将选择最显著的成分,如果这些成分有较大的均值差异时这种方法的表现会提升。
Hall研究成果提出,聚类中q的数量的选择,建议起始点用一个含较小数量的高排名成份,而不是仅仅用一个单个成份,并且用一个投影追踪的老方法去确定我们需要的成分的个数(例如变量或特征)。例如基于q个成份的k-均值聚类可以用来寻找聚类,并且用到的变量的数量可以从向量成分中排序选出,根据多峰性,通过在一个图中的平方和而不是识别出的聚类的个数来寻找“kink”。
斯蒂芬E. 芬博格(Stephen E. Fienberg,美国科学院院士,美国卡内基梅隆大学统计学和社会科学Maurice Falk教授)所做的研究报告是“对失能调查数据的多成员纵向模型”。我们通过混合一种交叉截面级别成员关系模型和纵向多变量潜轨道模型的特性发展了一族新的模型用于分析纵向数据。这些模型假定少数典型或极端个体的存在,并对他们在时间上的变化进行建模。我们通过把每个个体看作极端类群的凸的加权组合,从而在不同程度上把个体看作从属于所有这些类群。通过这种方式,我们能够描述显著的一般趋势(极端情形)同时能够说明个体的变异性。我们建议一种完全贝叶斯的设定,而估计方法时给予马尔科夫链模特卡罗抽样的。我们把我们的方法应用到国家长期关注调查(NLTCS),这是一个用于在65岁及以上的美国公民中评定残疾的状态和特征并带有六个复杂的波浪的纵向调查。我们方法的一个简单的推广使我们能够回答关于在代与代之间残疾状况变化的相关问题。
4、统计方法的误区与科学应用
随着统计研究的不断深入,统计方法和统计模型层出不穷,为学术研究提供了非常广阔的方法论选择空间,但是如果对各式各样的统计方法在理论前提和现实适用性等方面没有深入的充分理解,那么就可能会陷入统计方法的应用误区,可能得到不科学的结论。论坛特邀院士报告中有两位美国院士对统计方法的误区和科学应用做了讲演。
劳伦斯D. 布朗(Lawrence D. Brown,美国科学院院士,宾夕法尼亚大学统计学教授)所做的研究报告是“模型选择下的有效统计推断”。报告指出在数据分析之前常规的统计推断要求对于数据如何产生的特定模型做出假定。然而在应用中,我们经常进行各种各样的模型选择算法来决定一个更适宜的模型。这一过程往往涉及对原来模型的统计检验和置信区间。但是这些实际操作都被误导了。被估计的参数依赖于这个原来的模型,而且后来选出的模型的抽样分布可能具有很多意想不到的性质。这些性质和通过常规假定得到的性质非常的不同。置信区间和统计检验并没有像设想的那样很好的表现。当模型选择的过程本身就是各种各样的而且没有被充分理解的时候,尤其如此。我们研究被通常使用的高斯线性模型。除了在后模型选择推断中潜藏的问题,我们呈现一种用于对后模型选择参数做出有效推断的程式。这一程式不依赖于关于模型选择程式的知识。我们同样呈现该程式对于某些特殊线性模型设定的表现特征,以及涉及高维参数情形下的渐进性质。
劳伦斯·薛普(Lawrence Shepp,美国科学院院士,宾夕法尼亚大学统计学教授)所做的研究报告是“如何做好统计(How not to do statistics)”。薛普教授探索了如何把统计科学推向更高的应用境界,他指出科学研究如果脱离问题的本身,而盲目追求统计方法是比较危险的,这可能会得到一些具有误导性或者没有意义的结论。针对这个问题,薛普教授以其诙谐的讲演以“伪相关(spurious correlation)”、“猫狗识别”和“字符识别”三个研究实例进行了说明。在“伪回归”的实例中,他提到现在有太多的人盲目使用回归等统计方法,但是他们并不了解为什么要去做一个线性回归。他讲解了关于时间序列部分和(partial sums)的问题,具体内容是基于一个在统计届普遍知晓的“反正弦定理(arcsin law of probability theory)”,他论证到在实际中两个毫不相关的时间序列可能会具有很强的部分和经验相关系数,如果基于部分和经验相关系数则很可能会得到两个序列不独立的谬论。薛普教授进一步表示纯统计方法的研究和应用研究都有吸引人的地方,丝毫不能否认纯理论的基础重要性,但纯理论研究的应用一定要结合客观的现实问题,他希望统计学家能和更多的其他学科比如经济、生物、工程方面的专家联手,更多的关注问题的本身,而不要陷入繁杂的统计方法的研讨上。最后,薛普教授对他目前的重要研究进行了介绍。在美国,很多人都患有糖尿病,测血糖或者胰岛素的浓度就成了一个很必要的程序,但现有的手段工具的效率比较低,时间长、精度差,而且不方便。薛普教授与合作伙伴研究了一种新的简便测试糖尿病的统计方法,他们的研究能在五分钟内得到整个测量过程指导结果,并且测量费用也很低廉,但是目前精度不太理想,有很多噪声的扰乱,薛普教授目前正致力于过滤这些噪声。
二、经济社会统计研究
1、国民经济核算方法
在全球化背景下,国际经济交往的程度日益深化,形式也越来越复杂和多样化,这些变化给国际经济统计带来空前的挑战,国际经济统计由此成为一个颇具吸引力的研究领域。“全球化背景下的中国国际贸易统计数据”(高敏雪,中国人民大学统计学院)和“基于所有权的国民贸易差额核算”(吴海英,中国社会科学院)都认为,货物进出口贸易数据是衡量一国经济的重要指标,在全球化背景下,跨国公司在世界范围内布置生产链,通过外国商业存在拓展了传统意义上的跨境贸易,由此突显出传统跨境贸易统计的不适应性,国际贸易统计应当更加关注基于所有权基础的统计。
高敏雪指出直接投资所引起的附属机构的国别属性问题,搭建了从跨境贸易统计到属权贸易统计的基本框架以及调整方法,最后集中针对中国货物进出口贸易进行了分步、分口径的调整测算,并系统发掘了调整过程所包含的信息,为评价中国货物进出口贸易提供了不同的图景。调整的结果表明:中国货物贸易进出口的规模及顺差被高估了,而关于中国服务贸易状况以及与货物贸易的结构则需要重新认识。
吴海英则提出基于所有权的“国民贸易差额”(national trade balance)概念,通过与跨境贸易统计的比较,指出二者的关系为:国民贸易差额=跨境贸易差额+直接投资收益差额+雇员报酬收支差额。通过对美国、日本和中国三个国家国民贸易差额的实际核算,发现相比于跨境贸易差额所反映的全球贸易失衡程度而言,采用国民贸易差额方法反映的失衡状况要小得多。
“国际收支统计的最新进展以及对于中国的影响”(刘仕国,中国社会科学院)首先比较了国际收支手册第六版(BPM6)与第五版在对应账户上的口径变化,紧密结合近年我国经济发展趋势和参与国际的形式,从更广阔的背景下解释了新旧手册的改动及其意义。报告还深入探讨了BPM6对中国官方统计的影响,如从具体的服务贸易统计数额变动情况说明了口径变动的意义,进一步拓展到政治和经济外交等方面。
“普查年度GDP数据与常规年度GDP数据衔接方法研究”(施发启,中国国家统计局核算司)介绍了GDP的修订原则和修订方法,并对多种修订方法在实际应用中的效果进行评价和比较。最终得出如下两个结论:第一,最好的修订方法应为最小二乘内插法,其次为等速内插法,再次为趋势离差法和相关指标加权平均法,最差的方法为等差内插法;第二,最小二乘法、趋势离差法和等速内插法三种方法得出的结果彼此比较接近。此外,施发启还指出,要修订各产业历史增加值数据,应从最细行业入手,以保证各产业数据的可加性及其结构稳定性。
“基于地租方法核算的城镇土地出让金”(李静萍,中国人民大学统计学院)按照将土地出让金视为预收地租的方法,对我国城镇土地出让金进行了实际核算。核算结果表明,如果将土地出让金作为地租和隐性债务来核算,则核算结果对经济流量的影响不明显,但是会显著影响各部门的经济存量,尤其是政府部门的存量。李静萍认为,按照地租的思路对城镇土地出让金进行核算,可以充分揭示政府的“隐性债务”规模,而如果把土地出让金作为土地使用权资产的交易,则对于政府部门来讲只能体现为金融资产的累积,不能体现由于预支未来地租对未来政府融资能力的弱化。
“县域绿色GDP核算体系构建及其应用研究——以石家庄市井陉矿区为例”(刘德智,石家庄经济学院)指出,通过构建与县域特点相符的县域绿色GDP核算体系,找到县域经济发展与资源环境保护的契合点,可以促进县域经济的可持续发展。报告基于SEEA体系,构建出了一套切实可行、符合县域情况的绿色GDP核算体系,并以井陉矿区为例展开实际测算,通过对测算结果的研究,演示了县域绿色GDP核算对于产业结构调整和污染治理等的实际价值。
2、数据质量问题
“中国企业统计能力评估方法的研究”(王艳明,山东工商学院)和报告“DQAF方法下中美统计数据质量的对比分析”(刘小二,厦门大学)分别从微观和宏观两个层次阐述了统计数据质量的有关问题。王艳明的报告指出,企业数据收集的质量高低与企业统计能力的大小关系密切,定义企业统计能力=获取高质量数据的能力+企业统计分析能力+企业统计参与管理决策能力。报告认为企业统计能力的评估包括统计条件、统计内容以及统计应用领域等三个维度,并指出对企业统计能力的评价既可以从每个具体企业的统计能力进行评价,也可以从总体上对全国企业统计能力进行整体评价。报告还对评价指标体系和评价方法做了讨论。刘小二的报告指出,我国统计数据质量存在很多问题,突出表现在两个方面:统计数据与人们的实际感受不符以及数据“打架”现象普遍。报告介绍了国际货币基金组织的数据质量评估框架(DQAF),然后从质量的前提条件、保证诚信、方法健全性、准确性和可靠性以及适用性和可获得性等方面对中美两国的统计数据质量进行了详尽的对比,结果说明我国与美国存在较大差距,最后针对我国的情况给出了分阶段的对策建议。
“统计数据质量概念和数据评估的框架”(许永洪,厦门大学经济学院统计系)肯定统计数据质量在社会、经济分析中的作用,同时指出统计数据的质量的内涵和框架有待阐明和澄清。作者首先将统计数据质量的属性特征进行划分归类,在第一层次上将数据质量属性划分为四个特性,在第二层次上细分为六个,其次分别给出了统计数据质量广义和狭义上的概念,在上述基础上,分别针对广义、狭义的数据质量构建了评估模型,并建议了模型的适用群体,但对于报告中所构建的评估模型,作者也指出模型不能排除数据异常值的存在,同时强调了要注意统计方法的适用条件,根据实际情况选择适当的统计分析方法。
“计算机辅助问卷调查中敏感数据质量评价的探索性研究”(王瑜,中国人民大学统计学院)的研究是针对实际数据进行。作者指出已有的评价敏感问题调查方法的研究主要是通过比较不同方法的敏感行为发生率的高低,而运用回答问题时间来对敏感问题问卷质量进行评价的研究很少。她的研究以2006年《中国人性行为和性关系》调查数据为例,根据平均回答问题时间来筛选问题样本。她认为平均回答问题时间小等于3秒的数据都是异常的,而在大于3秒的数据中,以多类别Logistic回归来确定筛选问题数据的时间上限。然后控制性别、年龄、职业、调查地点、上网频率等变量,用线性回归模型计算各个样本平均回答时间的预测值,计算预测值和真值的差值,以差值的平均值为界,大于差值平均值的样本均认为是有问题的。最后她比较了问题样本对应的被调查者和其他的被调查者的特征,发现问题样本对应的被调查者的年龄较高、文化程度较低,上网的频率也较低,来自农村的比例更高,更多的是农民。而且该部分被调查者的自评价也表明,被调查者本人也认为问题敏感度偏高,或者对于问题存在的更多地不理解。相应地调查员给出的评价也显示问题样本对应的被调查者需要更多的帮助、诚实度偏低以及更多地表达过自己的看法。问题样本对应的被调查者的自评价以及调查员的评价之间在一定程度上得到了相互印证。因此她认为根据平均回答时间来进行问题数据的识别是可行的。
3、现实统计应用
“中国的就业增长、出口与创新研究——基于公司水平的比较研究”(吴翌琳,中国人民大学)关注就业增长与创新的关系。报告从地区、产业、所有制和公司规模等四个方面对就业增长进行了分解,结果发现:国内市场产出的增长对就业增长具有重要影响,其影响远高于出口的影响;创新对就业增长具有正的效应,但是该效应并不是很大。
“企业知识产权统计指标体系研究”(江苏大学,吴继英)指出企业知识产权能力是建设创新国家或创新地区的微观基础,将其定义为企业创造、应用、保护和管理知识产权的综合能力,在此基础上构造了包含4个一级指标、24个二级指标的指标体系,并利用层次分析法给出各个指标的权重。不过,鉴于无法获得数据,报告没有给出实际的评估结果。
“基于伯特兰博弈模型的人民币汇率合理性评估”(李宝新,河北经贸大学数学与统计学院)针对目前人民币汇率是否需要升值的问题,基于伯特兰博弈模型进行了实证分析。报告指出,实证分析结果表明,1990年至2007年人民币名义汇率一直处于币值低估状态,但自2005年起这种币值低估的态势开始扭转,并逐步趋近于博弈均衡汇率,为此,近期的人民币已不宜升值。
“基于环境Kuznets曲线的回顾以及在中国的适用性”(杨诗颖,首都经贸大学)围绕环境污染和经济发展二者之间的关系进行研究。报告阐述了Kuznets曲线的概念及其理论,借鉴国内外实证研究成果,从具体的数据、变量和模型选择等方面深入探讨了人均收入和环境污染之间的关系,给出了我国主要城市的曲线趋势和未来人均收入与环境污染的关系,具有较强的现实意义。
“城乡教育差距抽样调查问题分析”(洪畅,厦门大学)关注中国教育是否存在显著性的城乡差异,通过对样本数据的Wilcoxon检验,发现农村居民的教育水平显著落后于城镇居民,并由此而成为导致城乡居民收入差距的重要原因。此外,报告还指出,被调查者认为教育费用过高,希望政府提高对教育的转移支付。
报告“证券市场中股东的自组织模型”(曹湛,烟台南山学院)提出了一个比较新的模型概念——自组织模型,并把该模型应用于股份公司的结构中进行分析,从实际应用的角度为听众展示了模型的价值。
Nissim Ben David,Evyatar Ben David利用以色列足球联赛的数据,首次利用解析性的方法对比赛结果进行预测,并给出了相应的下注策略,通过确保各场比赛的不同正确率,从而以最少的赌资赢得最终的胜利。
4、生产率的分析与比较研究
“中国产业竞争力评估——与日本TFP水平的比较:1995-2006”(北京航空航天大学,郑海涛)从中日GDP增长率差异引出对两国TFP水平是否存在差异的问题,在介绍了基于购买力平价(PPPs)的TFP水平差异的比较方法之后,对中日两国以PPPs计算的GDP进行了比较,并进一步对中日两国产业TFP水平差异进行了比较。结果发现:在33个产业中,中国有26个产业的TFP(尤其是石油和初级金属产业)均低于日本,而且宏观经济层面的TFP水平也有显著下降的趋势。由此表明,中国的TFP尚未赶上日本的水平,并有扩大趋势。
“ICT对中国经济增长的贡献”(北京航空航天大学,孙琳琳)通过ICT资产价格的相对下降导致ICT资本对非ICT资本的替代引出ICT对中国经济增长贡献的关注,在增长核算的框架下,估算了各种投入的数据,最终分解出ICT对中国经济增长的贡献。结果发现:中国GDP的高速增长主要依赖于非ICT资本的投入,中国的ICT资本低于其他国家。
“基于DEA模型的涉农企业生产率评估”(安徽财经大学,宋马林)指出,涉农企业生产率的提升对于传统农业转型、发展现代农业以及建设新农村具有重要意义,认为DEA模型是一种更好的测度生产率的方法。报告首先采用六种不同的DEA模型对涉农企业生产率进行了测度,然后利用SABCB模型对不同模型进行有效的整合,为DEA模型的整合应用提供了新的思路。
5、金融统计和金融高频数据研究
第四届中国人民大学统计国际论坛在金融统计和金融高频数据方面共有4个session,来自世界各地的10位著名统计学者分别介绍了各自的最新研究成果。4个session具体涉及到了金融统计、金融高频数据分析和随机金融模型等研究领域。
Session1.4讨论的主题是金融统计模型,由英国伦敦经济学院统计系姚琦伟教授主持。三位演讲者分别是来自于美国罗格斯大学统计系的Rong Chen教授、美国南加州大学马歇尔商学院Yingying Fang博士和香港科技大学商学院信息系统、商业统计与运筹管理系郑星华博士。Rong Chen教授报告的题目是门限过程驱动的收益率曲线。政府公债利率是距离到期时间的函数,通常称之为收益率曲线。研究收益率曲线的动态行为并提供有效预测方法具有重要意义。报告利用Nelson-Siegal曲线对收益率建模,并假定模型的时变系数服从门限向量自回归模型。然后进一步讨论了模型的推断和预测方法,并提出了下一步研究方向。报告所提出的门限过程驱动的收益率曲线考虑了时变系数的体制变化,是对动态Nelson-Siegal模型的改进,为收益率曲线的建模和预测提供了有效方法。Yingying Fang博士毕业于美国普林斯顿大学运筹学与金融工程系,现为美国南加州大学马歇尔商学院助理教授。她报告的题目是线性混合效应模型的变量选择。报告针对线性混合模型的变量选择和参数估计问题进行了深入研究。提出了一类能同时对固定效应进行变量选择和参数估计的非凹惩罚profile似然方法,该方法具有模型选择的一致性。另外还提出了一类能同时对随机效应进行变量选择和参数估计的方法。两种方法都适用于模型维数随样本量指数增长的情况,并具有良好的统计性质。郑星华博士毕业于美国芝加哥大学统计系,现为香港科技大学商学院信息系统、商业统计与运筹管理系客座助理教授。他报告的题目是高维扩散过程的积分协方差矩阵的估计。报告研究了基于高频数据的高维扩散过程的积分协方差矩阵的估计方法,证明了在高维情况下已实现积分协方差矩阵的经验谱极限分布不仅依赖于积分协方差矩阵还与波动率过程的变化有关,因而不能很好地估计积分协方差矩阵,进而提出了一种新的时变调整的已实现协方差矩阵作为估计量。
Session1.8讨论的主题是金融高频数据分析,由中国人民大学张波教授主持。两位演讲者是来自于香港科技大学数学系的孔新兵博士和荆炳义教授。孔新兵博士演讲的题目是《Is There Evidence for the High Frequency Data Being Purely Discontinuous?》。孔新兵博士在其演讲中致力于解决金融资产价格建模中的一个重要问题:金融资产价格模型是否应该包含连续扩散成分。由于金融资产收益率序列的厚尾性导致在金融资产价格建模时需要包含不连续的跳成分,而有的学者甚至利用纯跳过程来构建金融资产价格模型,那么从金融高频数据中能否得到证据来证明纯跳过程足以构建金融资产价格模型?孔新兵博士在金融资产价格模型应该包含连续扩散成分的原假设下给出了一个检验统计量,并推导出了该检验统计量的渐近分布。数据模拟分析显示该检验统计量具有良好的统计性质及统计检验势。该领域现有研究多集中于跳检验统计量的构造,而孔新兵博士另辟蹊径研究连续扩散成分是否存在的检验统计量构造为高频数据资产价格建模提供了不同的思路。荆炳义教授演讲的题目是《Estimating the integrated Volatility under Noisy Observations of Semimartingales with Jumps》。荆炳义教授在其演讲中提出了积分波动率的一个新无偏估计量。该估计量的构造基于截断和先平均的思想,其对市场微观结构噪声和金融资产价格过程中的不连续跳成分均稳健。荆炳义教授推导出了该估计量的一致性和渐近分布。数据模拟分析显示该估计量具有良好的有限样本性质和渐近性质。积分波动率在金融风险管理、期权定价领域具有重要的应用价值,很多学者致力于积分波动率估计量的构造。荆炳义教授提出的估计量更符合实际情况下的数据特征,且与现有估计量相比具有更好的有限样本和渐近性质,是积分波动率估计量构造研究的一个重大进步,在金融实践中具有重要的应用价值。朱建平基于统计学方法论,介绍了金融高频数据的研究思路,强调要在金融高频数据研究中将统计分析方法与数据挖掘技术相结合。Liu Zhi针对高频数据构造了检验过程中是否存在跳跃的统计量,并讨论了该统计量的渐进性质和一致性等性质;在不存在跳跃的零假设下,证明了该统计量满足的中心极限定理;最后通过对不同形式Levy过程进行模拟,检验了该统计量的检验效果。
Session2.8讨论的主题是金融随机模型,由香港科技大学数学系荆炳义教授主持。两位演讲者分别是来自于中国人民大学统计学院的毕涛博士和上海立信会计学院数学与信息学院的Hui Gong。毕涛博士演讲的题目是《Dynamics of intraday serial correlation in China’s stock market》。毕涛博士在其演讲中对中国股票市场收益率序列的日内序列相关性进行了深入地探讨。他利用方差比检验来研究中国股票市场指数高频收益率序列的日内序列相关性,并据此得到中国股票市场不服从弱式有效市场假说的结论。他还基于异质市场假说研究了序列相关性与波动率之间的关系。大量实证结果显示金融资产价格过程存在显著的跳行为,毕涛博士在其研究中重点研究了序列相关性与跳之间的关系。实证结果显示在不同信息反馈水平上,序列相关性与波动率及跳之间存在复杂的相关关系。毕涛博士的研究促进了金融资产收益率序列日内序列相关性的研究,其对序列相关性与波动率及跳间关系的探索性研究加深了人们对中国股票市场运行过程和交易机制的认识和理解。Hui Gong演讲的题目是《Based on EGARCH model to Analyze Stock Returns of Apple Inc.》。Hui Gong在其演讲中对美国苹果公司股票收益率序列的条件异方差性进行了建模研究。他首先对金融资产收益率序列的典型特征及波动率建模方法进行分析和回顾;之后详细地介绍了EGARCH模型及相关检验;最后利用EGARCH模型对苹果公司股票收益率序列进行拟合。模型估计结果显示EGARCH模型可以很好地拟合苹果公司股票收益率序列的波动性,且该收益序列具有显著的杠杆效应。龚辉的研究很好地将EGARCH模型用于实际数据的建模中,对于探索波动率模型构建具有一定的意义。“Bayesian Approach to Markov Switching Stochastic Volatility Model with Jumps”(余超,中国人民大学统计学院)介绍了一个新的随机波动率模型,此模型是在综合考虑了价格过程的跳以及波动率的结构变化的基础上提出的。跳的部分可以捕捉到由于不正常市场行为所导致的大的价格变化而马尔科夫转换可以解决这些冲击对波动率的假的一致性。作者应用了基于MCMC及Gibbs抽样的贝叶斯方法对此模型进行了估计,经验分析表明此模型可以同时描述跳以及波动率的变化。
Session3.1讨论的主题是金融统计,由美国南加州大学马歇尔商学院Yingying Fang博士主持。三位演讲者分别是香港科技大学商学院李莹莹博士、英国伦敦经济学院统计系姚琦伟教授和美国康奈尔大学统计系Pengsheng Ji博士。李莹莹博士毕业于美国芝加哥大学统计系,现为香港科技大学商学院信息系统、商业统计与运筹管理系助理教授。报告的题目是基于高频数据的资产组合选择中的高维波动率矩阵估计。报告主要研究了如何利用高频数据对资产组合选择问题中高维波动率矩阵的估计问题,提出了逐对刷新时间(pairwise-refresh time)方法并结合TSCV方法估计波动率矩阵,证明了估计量的统计性质,能够为资产组合选择提供更精确的指导。姚琦伟教授报告的题目是高维波动率建模。报告结合因子模型和CUC方法对高维波动率建模,提供了一种既能刻画高维波动率的动态特征,模型形式又较为简单的方法,并对CUC方法提出了一种新的算法,该算法对维数非常高甚至几千维的情况都能适用。Pengsheng Ji博士报告的题目是具有最优相图的变量选择方法UPS以及L1与L0-Penalization方法的非最优区域。报告就线性模型的变量选择问题进行了深入探讨,引入相空间的概念,识别了三种变量选择状态对应于相空间的不同区域,并提出了具有最优相图的两阶段变量选择方法UPS,找到了L1与L0-Penalization方法的非最优区域,揭示了通常惩罚方法的非最优性并讨论了相关原因。该研究在变量选择问题的理论和方法上都具有一定的创新性。
6、风险管理与保险精算
风险管理与保险精算领域设有四个分会场,分会场主题分别是 “寿险、养老金和社会保障”,“风险管理与寿险”、及两个“风险管理与非寿险模型”。在寿险、养老金和社会保障分会场,中山大学岭南学院的宋世斌教授的“医疗保障制度的公共债务:中国步美国后尘?”。在介绍中国医疗保障制度的基础上,对比分析了我国与美国当前医疗保障体系面临的困境,测算分析了人口老龄化和医疗成本不断上升所导致的医疗保障成本不断增加的问题,对中国医疗保障制度的债务风险进行了测算,给出了实行部分积累、增加个人缴费率、延长退休年龄、建立医疗保障基金等控制债务风险等相关建议,对中国的医疗保障制度的改革与完善具有一定的参考意义。
华北电力大学的高建伟副教授的“企业年金税收优惠政策的精算分析”,在介绍中国企业年金地位及类型、企业年金的税收政策现状的基础上,将企业年金分为缴费、投资和分配三个阶段,得到税收支出的精算模型,并在不同的税收政策下考虑了企业年金的积累规模,设计了一个贡献率模型说明税收优惠政策的效应,通过实证分析,得出EET税收优惠政策对减少养老基金资金缺口最为有利的结论。
中国人民大学的王晓军教授的“中国社会养老保障支出风险的低估”。在分析中国养老金现状、问题和挑战的基础上,利用精算模型对养老金的未来收入与支出进行了测算,对养老保障制度财务可持续性进行了分析,对退休年龄、养老金调整指数、预期寿命、个人账户的继承权等变动对未来养老金收支的影响作了测算分析,指出当前国内外相关研究大多忽略了上述因素的影响,从而大多高估养老保险的收入、低估支出,通过实证,报告给出了低估的程度,分析了低估风险。该报告中的养老保险精算模型及其实证测算对我国养老保险制度的长期可持续发展具有一定的借鉴意义。
湖南大学的博士生罗琰报告了“基于随即微分博弈的保险公司最优决策模型”,考虑基于保险公司与自然之间二人—零和博弈的最优投资与再保险问题。运用随机控制理论,在假定了索赔、盈余、风险资产与无风险资产等随机过程的基础上,通过求解最优控制问题对应的HJB方程,得到了保险公司的最优投资和再保险策略以及最优值函数的闭式解。结果显示,在完全分保时,保险公司应全部购买无风险资产,而在自留额大于零时,保险公司的最优投资策略随风险资产与盈余过程间的相关系数、无风险资产回报率及终止时刻而改变。这为保险公司面临最不利经济环境时的风险投资及再保险策略提供了一个参考。
在“风险管理与寿险”分会场,中国人民大学的黄向阳副教授报告了“我国寿险公司利源分析评述:实务和精算规定”。针对利源分析“三差分解”原理,比较分析了我国两家寿险公司年报中关于利差损的表述、我国精算规定中的利源分析规定、精算教材中对利源分析的表述,指出利源分析的概念中存在的不清晰。比较了利源分析与管理会计相关概念的差异,定价方法对精算假设的影响,以及评估利率和定价利率在利源分析中的差别等。
北京大学的杨静平教授的“由二维Frechet copulas生成的分布混合近似二元copulas”的报告。在介绍copulas的概念和二元Frechet上边界、二元Frechet下边界、独立copulas三种重要的copulas类别及对应的关系的基础上,基于空间分解方法,介绍了如何用三种copulas描述二元随机变量的局部相依结构,并利用BF copula在保持原有边际分布的基础上近似原有copula的理论及方法,并用实例说明了这种近似方法的优越性。
天津财经大学的赵博娟教授的 “中国生育率下降结束?一个修正Lee-Carter模型的应用”。在介绍中国生育率发展趋势和特点的基础上,利用三次平滑参数建立了一个修正的Lee-Carter模型,在1988-2009年经验数据基础上,利用修正的Lee-Carter模型对中国城市、镇、农村的一胎、二胎及三胎等生育率进行了拟合和估计,分析了他们的特征及原因,指出任何地区、任何胎数的生育率都没有一直减少或停滞的迹象,预计在2009和2010年全国的婴儿数会增加。报告对我国生育率的评估及预测对我国计划生育决策具有一定的参考意义。
在风险管理与非寿险精算模型专题下,一共发表了九篇报告,内容包括非寿险公司的偿付能力评价,非寿险定价中广义线性模型和信度模型的结合应用,非寿险准备金评估的随机模型,巨灾风险管理模型及其应用,风险相关性度量的copula模型及其应用等,基本上涉及了非寿险精算研究的主要前沿课题,也是最近若干年非寿险精算研究的一些热点问题。
非寿险公司的偿付能力评价多年来一直是理论和应用研究的热点课题,上海财经大学的谢志刚教授从精算角度讨论了非寿险公司偿付能力的评价标准问题,并结合中国实际情况进行了实证讨论,体现了该领域的最新研究进展。非寿险准备金评估的随机模型在最近若干年发展迅速,也得到了精算实务界的极大关注,南开大学的张连增教授对非寿险准备金评估的对数正态模型进行了完善,而天津财经大学的刘乐平教授提出了一种基于贝叶斯信度对准备金进行区间估计的方法,这些都是对现有准备金评估随机模型的推进。在精算学的理论和应用研究中,风险的相关性度量显得越来越重要,而copula作为相关性度量的工具之一,其价值也日益得以体现,北京大学的郑延婷和杨静平教授提出了一种对二元copula进行分块近似的方法,并将其应用于期权定价进行了实证检验,是copula应用研究的重要成果之一。广义线性模型和信度模型是非寿险定价最主要的方法,其结合应用是避免定价信息重复使用的主要途径,也是非寿险精算研究的热点问题之一,中国人民大学的孟生旺教授在几种不同的分布假设下提出了一种考虑个体风险特征的信度模型,从而把广义线性模型和信度模型进行了有机结合。巨灾风险管理是人类共同面临的一个重大课题,中国人民大学的肖争艳副教授应用极值理论的方法,对中国的地震数据进行了分析,得出了一些有价值的结论。
7、抽样调查研究
缺失数据研究“PPSWR抽样下的缺失数据插补”(邹国华,中国科学院数学与系统科学研究院)针对抽样调查中存在的项目无回答现象,指出目前简单随机抽样下比率插补、回归插补、随机插补等方法的缺点,进而提出在多阶段抽样的初级阶段采用PPSWR抽样,然后对项目缺失数据进行插补的方法,讨论了该方法下均值估计和方差估计的问题,并进一步将该方法运用于未知回答概率的情况。最后对该方法进行计算机模拟实证,对抽样辅助变量分别假设三种不同分布,各进行100、500次模拟,结果验证了该方法下目标估计量更接近于总体真值,同时指出jackknife方差估计方法对该方法的适用性。“存在不可忽略缺失数据多维梯度响应模型的贝叶斯估计”(陶建等,国家教育部应用统计学重点实验室,东北师范大学数学与统计学院),基于教育测评中数据缺失并非随机缺失或完全随机缺失的现象,提出了用于分析具有不可忽略缺失数据多维项目反应理论(IRT)模型的贝叶斯方法,将Sahu的有效数据扩展方案拓展到多维模型和多分支模型,拟合了适合响应值的多维梯度响应模型和适合缺失数据的多维两参数logistic模型。作者在吉布斯抽样的基础上,采用了MCMC算法,提出了一种可以在不可忽略缺失数据机制下扩充数据,从而估计多维梯度响应模型参数的方法。数据模拟结果显示,忽略数据缺失机制导致项目参数估计发生相当程度的偏倚且偏倚的增加满足这样的函数形式,该函数由待测量相关关系和支配数据缺失机制的潜在变量构成,进一步地,结果还显示这种偏倚可以通过NONMAR模型来降低,该模型还可以用于纵列数据、题组和多级响应模型。
“普查事后调查:理论分析及在中国的实践”(陶然 金勇进,中国人民大学统计学院 应用统计研究中心)从普查的误差来源着手,在回顾了检查普查数据质量的两大方法体系后,着重研究事后调查,列举了国外事后调查的实践经验和历史,分析了事后调查的净误差估计和双系统估计,并比较了事后调查两种方法的特点和应用,同时也指出了事后调查方法的缺陷和不足。最后对如何改进事后调查方法在我国的应用进行总结并提出了一系列建议。
在重抽样方法研究分会场,Francis Bach提出将表现为非线性交互作用的原生变量定义为以指数方式呈现的正定核函数,在此基础上采用线性选择非线性变量,指出在一定假设条件下,规范化框架允许一些呈指数形式的不相关变量作为观察变量;Xuming He给出一类权重分布满足渐近有效的条件,从而产生Wild bootstrap方差估计的线性回归M估计量,并说明该方法在有限样本条件下的适用性。Yichao Wu将目前仅能用于最小二乘回归的LAR算法扩展用于其它模型,提出将LAR模型进行扩展,通过将常微分方程系统进行分段给出相应的求解路径,使之适用于一般线性模型和似然模型。
8、信心指数专题研究
统计国际论坛的一个分会场是2010年第二季度两岸四地消费者信心指数发布暨学术研讨会。此次会议由中国人民大学中国调查与数据中心主办,首都经贸大学统计学院、中央财经大学统计学院、香港城市大学管理科学第、澳门科技大学可持续发展研究所、台湾辅仁大学统计资讯系合办。
袁卫常务副校长出席会议致辞并发布了2010年第二季度两岸四地消费者信心指数。中国人民大学中国调查与数据中心副主任彭非教授,对2010年第二季度两岸四地消费者信心指数进行了总体评析。首都经贸大学纪宏教授、香港城市大学管理科学系吕晓玲博士、澳门科技大学可持续发展研究所庞观权先生、台湾辅仁大学统计资讯学系谢邦昌教授对大陆、香港、澳门、台湾2010年第二季度消费者信心指数进行了分别评析。中央财经大学统计学院院长刘扬教授介绍了消费者信心指数的编制技术。
出席此次会议的有人民日报、新华社、光明日报、凤凰卫视、香港无线电视、东森电视、中天电视等三十多家媒体。2010年第二季度两岸四地消费者信心指数的主题为 “信心期待未来”,总体上呈现出五大特点:
(1)消费信心稳定 酷暑考验复苏
2010年第二季度,大陆、香港、澳门和台湾的消费者信心指数分别为89.8,86.4,81.0和70.7。同比2009年第二季度,大陆消费者信心指数降低9.3,但仍在90点左右,为四地最高;香港和澳门信心指数分别降低1.1和0.2,台湾则大幅提高15.7。环比2010年第一季度,大陆,香港,澳门和台湾四地的信心指数有微弱的下降,分别降低2.5,1.7,1.8和1.4。
从最近一年消费者信心指数的走势来看,随着全球经济形势的好转,大陆、香港和澳门消费者信心指数震荡企稳,台湾消费者信心指数则从低位回升。从两岸四地消费者信心的各项分指数来看,在物价、投资方面仍有隐忧。
(2)经济信心积极 就业压力犹存
本季度,大陆和澳门消费者信心经济发展分指数均处于积极水平,分别为117.0和107.1。环比2010年第一季度,大陆和澳门经济发展分指数出现4.9和3.0的下滑,而香港经济分指数略有下降,为98.0点,处于中性水平;但同比2009年第二季度,香港和澳门经济发展分指数有显著提高,分别上涨12.9和14.2点。台湾经济发展分指数处于较低水平,本季度为60.3;但无论环比2010年第一季度,还是同比2009年第二季度,指数均有上升,上升幅度分别为0.4和8.7。
随着经济形势的向好,四地就业压力有所缓解,但四地消费者信心就业分指数均低于经济发展分指数。本季度,大陆、香港和澳门就业分指数分别为94.2,91.9和93.4,与上个季度相比,三地分别下降2.7,7.2和3.9点;台湾就业分指数为49.8,虽有1.5点的上升,但仍处于消极的水平。
(3)通胀差异显现 生活依旧乐观
本季度,两岸四地居民对物价方面的信心呈现出一定的差异性,整体而言物价指数绝对水平均不乐观。大陆消费者信心物价分指数为76.4,比上季度显著提高5.9点,说明大陆地区物价信心有所好转;香港和台湾物价分指数与上季度相比变化不大:分别为65.2和47.3点,环比轻微下降了1.6和0.4点;而澳门物价分指数为54.2,与上季度相比有显著地下降(下降5.9点)。
整体而言,港澳台三地的物价信心水平均不乐观,本季度澳门物价信心有明显下降;而大陆地区物价信心有好转趋势。四地居民对于物价信心消极的态度并没有太多影响其家庭物质消费:从反映居民家庭消费状况的消费者信心生活分指数来看,本季度大陆生活分指数为116.9,较为乐观;香港和澳门的生活分指数分别为109.4和94.8,近一年来虽有波动,但基本是中性偏向乐观。台湾生活分指数为61.7,虽仍处于低位,但已是连续6个季度上扬,且一直高于经济发展分指数。
(4)民间投资怎奈熊市 股市振荡信心逆转
从居民投资股票和基金的状况来看,本季度,大陆、香港、澳门和台湾的消费者信心投资分指数分别为69.0,90.8,88.8 和107.7。相比上一季度,大陆、澳门和台湾的投资分指数有大幅下降,其中:大陆下降13.6点,澳门和台湾分别下降7.1和7.9点。香港投资分指数降幅最小,本季度下降2.2点,为90.8。上述指数表明,居民投资信心受股市震荡影响,呈现显著波动。
本季度,大陆、香港和澳门消费者购房信心分指数在经历了近一年的持续下跌后,首次出现不同程度地回升,分别为65.1,63.4和47.8,上升2.2,5.3和10.3点,反映消费者购房信心有一定好转。而在三地回暖的同时,近一年一直处于上扬趋势的台湾购房分指数则出现下降的逆转,大幅回落14.9点,至85.8点,甚至低于去年同期水平。
(5)消费信心预期向好 物价投资影响显著
消费者信心指数及各分指数均由“现状指数”和“预期指数”构成,反映消费者对现状的评价和对未来三个月的预期。大陆、香港和澳门预期指数均高于现状指数;从各分指数来看,大部分预期分指数好于现状分指数,显示出三地消费者信心预期向好的趋势。而台湾消费信心预期指数则一直低于现状指数,说明台湾居民消费信心的预期略显悲观。
在消费信心总体向好的背景下,物价和投资对消费者信心的消极影响最为明显。本季度,大陆、香港和澳门的物价分指数分别为76.4,65.2和54.2,购房分指数分别为65.1,63.4和47.8,虽然购房分指数触底后有明显回升,但仍远低于各地的消费者信心指数。投资分指数各地也有显著下降。说明通胀压力、投资不稳和过高房价是影响消费者信心恢复和经济复苏的障碍。
三、现代统计方法前沿
1、高维复杂数据研究
随着人类科学技术的飞速发展,许多科学研究领域产生了多种多样的海量超高维复杂数据。这些领域包括基因学,天文学,宇宙学,流行病学,经济,融学,功能性磁共振成像以及图像处理等领域。面对这些高速增长的复杂超高维海量数据的挑战,要求各个领域的科学家具有快速提取他们所需信息的能力。因此,就统计学自身而言,通过对这些复杂数据的统计推断,研发出强有力的统计科研工具,这显然会给统计界带来切实的利益:将有利于统计学科理论和方法在更广阔的天地中长足发展,有利于促进对自然和科学的深度理解。
“再拟合交叉验证”(Fan)考虑了模型 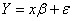 中 中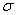 的估计及相关的问题。 提出的RCV方法的目的有两个,一个是估计 的估计及相关的问题。 提出的RCV方法的目的有两个,一个是估计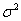 和选择模型,再者是处理伪相关。这种方法具有神谕性质,并且比直接方法和简单两步法有更小的偏差。该方法只需要带有 和选择模型,再者是处理伪相关。这种方法具有神谕性质,并且比直接方法和简单两步法有更小的偏差。该方法只需要带有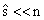 的确定筛选,过拟合的产生是由于在实现噪声和协变量之间的伪相关,对于极端维度的情况这种过拟合会更严重。 的确定筛选,过拟合的产生是由于在实现噪声和协变量之间的伪相关,对于极端维度的情况这种过拟合会更严重。
“协方差结构的统计推断”(Cai)指出高维数据分析已经上升为统计科学研究界的重要挑战和机遇。它包含两个常见的特征:总是大量维度或大量数据集,稀疏性(只有一小部分观测包含信号),即有“海底捞针”的含义,高维例子有基因学、fMRI分析、天体物理学、信号检测,和大p小n问题,即有稀疏性和高维问题,我们的研究从非参数回归(线性估计,小波门限选择)到大p小n回归(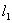 最小化方法),最后研究到大型协方差矩阵的推断上。 最小化方法),最后研究到大型协方差矩阵的推断上。
“关于高维回归的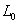 正规化”(shen)研究了回归模型: 正规化”(shen)研究了回归模型: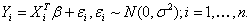 ,其中相应变量 ,其中相应变量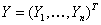 ,预测值 ,预测值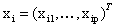 是p维的。特征选择,用非零系数或 是p维的。特征选择,用非零系数或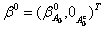 的估计去识别预测值,高维d特征选择的优势是:带有较高预测能力的简单模型,这种方法的困难是计算和理论上的挑战,特别是当 的估计去识别预测值,高维d特征选择的优势是:带有较高预测能力的简单模型,这种方法的困难是计算和理论上的挑战,特别是当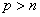 的情况下。 的情况下。
“两个非线性高维方法:VANISH和FAR方法”(Hames)研究了线性回归的高维问题。
“高维波动率的模拟”(Yao)用到的建模技巧是将因子建模与CUC方法结合,其中因子建模是基于特征分析而CUC也是特征分析的新算法。
“用高频数据做投资选择的大型高频矩阵估计”(Li)考虑了Markowitz投资组合问题 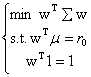 ,其中 ,其中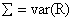 ,解 ,解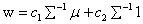 。CAPM和许多投资理论都是以其为现代财经理论的建立为基石的,上述值对投入向量和他们误差的估计很敏感,根据Green and Holdfield(1992); Fan, Zhang and Yu(2008) 指出它能够引起极短效应,特别是对大量投资问题而言。 。CAPM和许多投资理论都是以其为现代财经理论的建立为基石的,上述值对投入向量和他们误差的估计很敏感,根据Green and Holdfield(1992); Fan, Zhang and Yu(2008) 指出它能够引起极短效应,特别是对大量投资问题而言。
“基于Le Cam定理的近期研究”(Zhou)介绍了Le Cam定理的近期研究情况。他们与Brown,Cai,Zhang和Zhao联合近期研究方向为非参数密度估计的新方法,Nussbaum (1996, AoS) and Low and Z. (2005, AoS) 提出了非参数密度估计,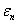 : :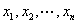 是独立同分布于密度 是独立同分布于密度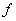 ,带有变量密度的泊松过程是 ,带有变量密度的泊松过程是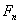 : :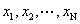 独立同分布于密度 独立同分布于密度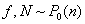 ,高斯白噪声 ,高斯白噪声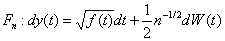 ,在未知的弱假定条件下上述值是渐近相等的。 ,在未知的弱假定条件下上述值是渐近相等的。
“高维可加模型的稀疏正则化问题”(Yuan)首先介绍了高维可加模型,预测值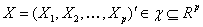 ,相应变量 ,相应变量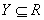 ,预测模型是 ,预测模型是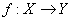 ,对回归模型 ,对回归模型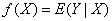 ,分类模型 ,分类模型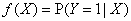 和其他的广义回归模型。 和其他的广义回归模型。
“高维数据异常诊断的一个压缩PCA子空间方法”(Kolaczyk)提出,对于多元过程的异常检测,异常的定义就是偏离通常或常见的顺序、规则或形式。异常检验指的是要么是“定时的”,要么是“事后的”,是一个控制的关键,它的可靠性和稳定性和一切安全性,与异常检测相关的例子包括,基因药物作用机制的鉴定,化学过程控制,财务管理,网络安全,录像监控等等。
“高维网络推断”(Peng)讲的是遗传基因交互作用在在病因学方面扮演了重要的角色,较强的交互作用指的是在mRNA表达水平上是显著相关的。大量的微阵列技术使得在同时期对同一实验的对数千基因的同时检验mRNA表达水平可用。
“高维自适应非线性交叉结构的变量选择”(Radchenk)提到近来对传统线性回归模型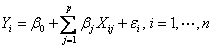 的估计越来越受到重视,其中预测值的数量为p,它比观测值的个数大很多,首先我们通过包含交叉项去除可加性假定,用标准两种交叉模型 的估计越来越受到重视,其中预测值的数量为p,它比观测值的个数大很多,首先我们通过包含交叉项去除可加性假定,用标准两种交叉模型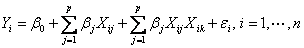 ,我们将上述模型推广到更广泛的非线性领域 ,我们将上述模型推广到更广泛的非线性领域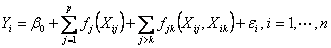 。 。
“用于正则化回归估计推理的一个摄动方法”(Tianxi Cai)提到高维数据分析往往旨在确定一个具有重要特性的子集和评估它们对结果的效应。基于标准回归方法的传统统计推断模式往往不能呈现高维数据的特征。在最近几年,正则化的方法已成为用于分析高维数据有效的工具。这些方法选择重要的特征,同时对它们的效应给出稳定的估计。例如自适应LASSO和SCAD能给出一致的和渐近的具有神谕性质的正常估计。然而,在有限样本下,它仍然不能获得回归参数的区间估计。在本文中,我们提出摄动重采样的程式来近似一类惩罚参数估计量的分布。根据渐近理论,我们提供了一种简单的方法估计协方差矩阵和置信区域。通过有限样本模拟,我们验证了该方法能够提供准确推断,并且把它与其他广泛使用的标准差和置信区间估计作比较。我们也通过一组用于研究艾滋病毒抗药性与大量基因突变关系的数据集来展示了我们的方法。
2、统计模型研究
Xi Luo博士(University of Pennsylvania)作了题为Average Case Analysis of Sparse Multivariate Regression under Noise的报告。本报告讨论不完全的带有噪音的稀疏的多通道信号的恢复。使用的方法是对未知的回归系数进行带有惩罚的最小二乘估计。与通常使用的最差案例分析相比,平均案例分析在更弱的假设下给出了更优的结果。本报告提出两步方法估计各通道的信号,得到了更低的平均均方误差。最后对所提方法进行了数据模拟分析。
Wheyming T. Song博士(National Tsing Hua University)作了题为 A Finite-Memory Algorithm of Batch Means Estimators in Estimating the Variance of the Sample Mean in Statistical Experiments的报告。在统计试验中一个经典的问题是估计点估计的方差,问题的原型是平稳自相关过程的样本均值。传统的批量平均值法需要事先知道样本量。本报告提出对该方法的改进,不需要事先知道样本量。所提方法对过程长度是随机的并且很大的统计试验尤其有用,比如在流感疾病控制中用来评价各种控制方法的预防效果。
吕晓玲博士(中国人民大学)作了题为Kim's Model or Bhat's Model for Time-use Decision的报告。本报告对比了两个在效用函数最大化框架下的时间分配问题的统计模型。Kim et al. (2002) 所提模型假设误差分布为多元正态,Bhat (2005) 假设误差为极值分布。本报告通过模拟分析了两个模型参数估计和模型拟合问题,并且应用kim 模型分析了香港交通出行者不同活动的时间分配问题。
Alicia Carriquiry博士(Iowa State University)作了题为 Density Estimation for a Non-Gaussian Random Variable Observed with Measurement Error - Applications to Dietary Assessment的报告。几乎每个国家都进行膳食调查,从而了解整个人群的健康状况,为食物调配政策提供参考。为了控制费用,通常只调查每个受访者一至两天的食物摄入,尽管公共卫生更关注的是居民长期的食物摄入和营养状况。令Y和y分别表示日摄入量和通常摄入量,u表示测量误差,并且y与u之间不独立,则Y=y+u。Y的密度函数f=fy*fu,为两个密度函数的卷积。因此对fy的估计为在给定服从密度f的观测值下对含有观测误差的随机变量的密度估计。针对数据的非正态性和噪音影响,本报告提出了一个具有优良性质的对fy的估计方法。本方法为半参数方法易于实施,目前被世界很多政府机构、研究群体和组织单位使用。
Jiayang Sun博士(Case Western Reserve University)作了题为 New Approach to Estimation for Data with General Measurement Error的报告。本报告在误差分布已知和未知情况下,提出了一个对带有测量误差的数据的密度估计方法,该方法是对Non-Fourier估计和混合估计的结合。
Linda Zhao博士(University of Pennsylvania)作了题为 Learning from Crowds的报告。在有指导的学习中,对于一个观测通常很难获得客观准确的标签,而是从不同方面获得主观的带有噪音的多个不同的标签。针对此问题,本报告提出了一个概率方法评价不同标签并给出真实的隐藏标签的估计。实际数据分析表明新方法由于通常使用的多数投票方法。
Manyu Wong博士(Hong Kong University of Science and Technology)作了题为 Three Estimators for Poisson Regression Model with Measurement Error的报告。本报告提出三种带有测量误差的泊松回归模型的参数估计方法。在假设测量误差正态分布,潜变量和可观测变量之间相关系数已知的情况下,新的系数估计仅需调整原有估计,无需考虑测量误差。最后通过模拟方法研究了估计量的相合性和渐近性。
艾春荣博士(上海财经大学)作了题为 A Unified Theory of Functional Coefficients Models的报告。本报告考虑了参数为协变量的函数的模型推断问题。提出的方法是将函数的系数用sieves替代,并且以此近似形式对模型进行估计。在一些充分条件下,估计是相合、渐近正态估计。
Xinyu Zhang博士(Chinese Academy of Sciences)作了题为 Model Averaging by Cross Validation的报告。模型的组合技术是降低模型参数估计风险的常用方法。本报告讨论了对带有异质性和自相关误差的因变量条件均值的估计。提出的模型平均的方法,通过最小化交叉验证指标对模型权重进行优化。在平方损失下,该方法可证明是渐近最优的。模拟和实际数据都表明该方法很好的拟合了数据。
“Projection Based Scatter Depth Functions and Associated Scatter Estimators”(Xin Dang, Department of Mathematics University of Mississippi University)介绍了scatter depth functions 及其很好的性质。基于scatter depth的投影满足很好的性质,并且其样本具有强以及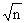 阶的一致相合性。在一些正则条件下,得到了scatter depth functions的经验过程的极限分布,其影响函数有界。进一步的导出了一个基于仿射等价scatter的最大depth。得到了样本scatter 的估计量的极限分布并证明了强以及阶的一致相合性。相关scatter的估计量的有限样本的行为显示出其有高稳定性及高效性。 阶的一致相合性。在一些正则条件下,得到了scatter depth functions的经验过程的极限分布,其影响函数有界。进一步的导出了一个基于仿射等价scatter的最大depth。得到了样本scatter 的估计量的极限分布并证明了强以及阶的一致相合性。相关scatter的估计量的有限样本的行为显示出其有高稳定性及高效性。
“对广义的帕累托分布改良的似然性方法”(Yongcheng Qi,美国明尼苏达州得卢斯大学)介绍到最大似然法可以用来估计帕累托分布的参数,但因为帕累托分布的非规律性,所以在某个区域里这个方法不能估计它的形态参数。Yongcheng Qi的研究提出了一种新的似然估计的方法克服了这个问题,使得在所有区域里都可对帕累托分布的参数进行估计。
“用交叉验证法进行模型平均”(Xinyu Zhang,中国科学院数学与系统科学研究院)指出模型平均法被广泛用来减少估计时错误的风险。Xinyu Zhang的研究主要是用异方差和自相关干扰来估计响应变量的条件均值。他提出一个模型平均的方法,主要是用最小化交叉验证准则的方法来获得权向量。他展示的这个模型平均法的参数是渐近性最优的。最后他还展示了模拟的结果和实际数据分析的结果,都证明了这个方法的优点。
“用广义的非循环有向图来识别非线性向量自回归模型”(Wei Gao,西安财经学院)利用在非循环有向图里顶点代表着不同时间的随机变量,边代表着变量间的因果关系。她提出了非线性时间序列模型家族的定义,这个家族也可以用非循环有向图来表示。时间序列变量之间的条件独立性关系可以用条件互信息统计和置换过程来证明。一般的条件互信息和线性条件互信息联合靴带法之间的差异被用来验证因变量的非线性。为了确定非线性向量自回归模型里同时发生的因果联系,广义似然比统计可以用来确定同时发生的变量之间的因果方向。而基于非参的最大似然估计的条件靴带法可以用来逼近检验统计量的分布。最后她还展示了她用模拟数据验证的结果。
Samuel Kou(哈佛大学统计系)的报告主题是“异方差层级模型的最优压缩估计”(Optimal Shrinkage Estimation in Heteroscedastic Hierarchical Models)。本文利用James-Stein压缩估计的思想,建立了异方差层级模型的SURE(Stein’s unbiased risk estimate)估计量。作者证明了该估计量的在理论上的最优性,然后用这种估计量处理了几组模拟数据和一组实际数据,表明该方法有一定的实用性。
Changjiang Xu ,A. Ian McLeod讨论了一般信息准则的性质及其在惩罚MLE模型选择中的适用性,并用糖尿病的实验数据进行了实证研究。
Chi-Chung Wen以骨折数据为分析背景,在假定数据服从比例风险模型的前提下,针对协变量缺失的现状数据构造了非参数极大似然估计法,并通过模拟数据和真实数据验证了非参数极大似然估计的效果。
3、渐近理论的前沿研究
报告“基于局部方法的广义估计方程的权重”(Ian McKeague, 哥伦比亚大学)讨论了在生物医学中簇生和相关数据分析中产生的如何计算广义估计方程(GEE)的权重的问题,已有的计算方式是基于固定方法的,一种更严格精确的计算方式是基于局部方法的。虽然这样的权重分析已经是标准的渐进有效性理论的一部分,但以前却从未应用到GEE中。他们的结果(与Zhigang Li合作)表明已有的基于固定方法的方式对于线性模型可以提供可靠的权重计算。然而在带有可交换相关结构的logistic回归的Wald检验的重要的特殊情况,已有的方式将使得拒绝的样本容量变大大约10%,而局部渐进方法可以精确到2%。
报告“无限维指数族的极大似然估计”(David Pollard, 耶鲁大学)解释了Dou, Pollard和Zhou用过的关于极大极小问题函数估计的关键论证的一个简化版本。主要内容是:维数随着样本容量增大的参数估计的凹凸法则,一个技巧的变化来去除有偏项。
报告“非光滑泛函的估计”(Mark Low, 宾夕法尼亚大学)指出对于极大极小风险,当估计任意一个泛函时,一个一般的下界可以给出。边界是基于两个复合假设。这是有效的对于估计多元正态观测的均值的L1模。基于渐进理论和Hermite多项式,渐进的灵敏的极大极小率的最优估计将被构造出。注:本文合作者为Tony Cai
4、观测研究中的因果推断
“重复交叉截面观测学习中的因果推断”(Bo LU)指出对于不管是二值处理还是多水平处理的交叉截面设计,因果关系的推断已得到广泛的研究。但对不同参与者在同一时间进行重复测量的交叉截面研究这种讨论还很少。这种设计具有一个时间成分,但它不同于那种对同一个体在多个时间进行观测的纵向观测学习。在健康研究中,一个有希望的/成功的项目经常采用本质上一样的方式在同一时间点进行重复。我们的研究是由一个意大利的戒烟项目所激发的。这个项目从2001年到2006年进行重复,目的是比较药物加顾问服务与只有顾问服务这两种策略对戒烟的效果。这次演讲针对这个重复的交叉截面研究设定可能的结果体系,识别对于有效的因果效应估计的假定,讨论检验某些假定的可能途径并对未检验的一些假定进行灵敏度分析。一个相配的估计方法被用于分析这个实际数据。
“当协变量只在离散时间点上被观察时对连续时间过程的因果推断”(Dylan Small)介绍到:在纵向数据中大多数对因果推断的关于G估计的工作都假定一个潜在的离散时间数据生成过程。然而,在有些研究中,假定数据是由协变量只在离散时间被观察的连续时间过程生成的是更为合理的。对于这种设定,我们研究为提供相合估计对离散时间G估计所需要的假定,同时我们呈现一种在比一般离散时间G估计更弱的条件下建立相合估计量的新方法。我们用我们的新方法来研究痢疾对儿童身高的影响。这一工作是和张明远以及Marshall Joe一起完成的。
5、对函数型数据的正规化方法研究
“函数型梯度的可加建模”(Fang Yao and Hans-Georg Mulle)旨在研究在观察到函数型预测变量和标量型响应变量的函数型回归设定情形下的函数型导数和梯度的估计问题。导数被定义为函数型方向导数,它们能够指示在特殊函数方向的预测功能的变化如何引起在标量型响应变量中相应的变化。为了得到一个不依赖模型的方法,维度轨迹航行需要施加适当的结构性制约。因此,我们提出在可加回归框架内对函数型导数进行估计。这里函数型导数的可加成分和具有预测过程的函数型主成分的一维非参数回归的导数是相关联的。这种方法只要求估计一维非参数回归的导数,因此在计算上是非常简单实施的,同时也提供了实质性的灵活性,快速计算和渐近相合性。我们通过整个生命周期的生殖能力对早期生殖轨迹的依赖性研究来展示功能导数和梯度的估计和解释。
“利用双向正则化奇异值分解对双向函数型数据进行分析”(Haipeng Shen:)指出双向函数型数据包含一个数据矩阵,这个矩阵它的行和列,都是有结构的。比如暂时的或者空间的,当数据是在空间中的不同地点收集的时间序列。我们通过对数据矩阵的奇异值分解(SVD)中的左右奇异向量引入正则化把单向函数型主成分分析(PCA)推广到双向函数型数据。我们集中在一个惩罚途径上,并解决从单向回归惩罚构建恰当的双向惩罚这一不平凡的问题。我们引入条件交叉验证光滑参数选择也就是左奇异向量在右奇异向量条件下交叉验证出来,反之依然。这一想法可通过看过另一个最优化算法的一部分来实现。另外除了惩罚途径,我们简单考虑了基于基展开的双向正则化方法。所提出的这些方法在模拟学习和实际数据例子中进行了描述。
6、纵向数据模型研究
“区组数据的相关结构的模型选择”(Annie Qu)指出由于相关结构的模型选择相对于仅有协变量的模型选择而言,涉及更高阶的矩,它正成为一个具有挑战性的问题。然而,对相关结构的正确刻画对提高针对区组数据的估计量的估计效率起着很重要的作用。我们的策略是利用一系列待选的基矩阵和涉及很多基矩阵的惩罚模型来尽可能的近似相关矩阵的经验估计量。该方法不但不需要似然函数而且在计算方面是高效的。另外,它能够通过从很多基矩阵中进行成对选择策略来识别复杂的相关结构而且它可以应用到离散和连续的响应数据。理论上,我们展示了该方法具有相合的选择真实相关结构的神谕性质以及当真实结构已知时估计的相关参数具有同样渐进正态分布的性质。我们的模拟实验和数据例子显示该方法在选择真实结构方面是有效的。
这是和Virginia大学的周建辉的联合工作
“利用双惩罚REML方法选择固定效应和随机效应”(Peter Song)强调在分析区组数据和纵向数据时,线性混合效应模型(LMM)具有非常广发的应用。在LMM的实际应用中,对随机效应部分结构的推断对得到个体响应的恰当解释和做出准确的统计推断具有很重要的作用。当在分析中具有非常多固定效应和随机效应时,这个推断任务就变得显著的具有挑战性。变量选择的困难来自我们需要同时正则化均值模型和协方差模型并且对这两个模型中的一些参数要进行限制。在这次演讲中,我们将呈现在LMM中利用双正则化的限制极大似然的一种新方法来同时选择固定效应和随机效应。为保证选取的随机效应的协方差矩阵具有正定性,我们采取了Cholesky分解。相对于出现在Cholesky分解中的排好序的预测变量,随机效应时不变的。接着我们发展了一种新的算法用于有效的解决相关的最优化问题。这种算法的计算消耗是能够和LMM中用于求解MLE或者REML的Newto-Raphson算法相比较的。我们也研究了该方法的大样本性质其中包括神谕性质。模拟学习和数据分析都用来进行描述。
7、现代分位回归
现有的分层模型的理论本质上说就是有关给定预测变量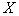 的值 的值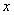 后响应变量 后响应变量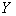 的条件均值 的条件均值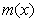 的理论。这些理论没有也不可能给出响应变量的条件分位函数的全面刻画. 所以,考虑给定协变量的条件下响应变量的全面刻画问题、估计子的稳健问题等等,就显得非常必要了。举个例子说吧:我们很想知道具有分层结构的数据里,某个协变量是否对响应变量的不同层面有不同的影响?什么时候产生的不同影响?产生的机理是什么?等等。再比如说,怎样解释1992年美国民主党所提出的美国人出现了两极分化问题:穷的越穷,富的越富? 的理论。这些理论没有也不可能给出响应变量的条件分位函数的全面刻画. 所以,考虑给定协变量的条件下响应变量的全面刻画问题、估计子的稳健问题等等,就显得非常必要了。举个例子说吧:我们很想知道具有分层结构的数据里,某个协变量是否对响应变量的不同层面有不同的影响?什么时候产生的不同影响?产生的机理是什么?等等。再比如说,怎样解释1992年美国民主党所提出的美国人出现了两极分化问题:穷的越穷,富的越富?
另一方面,Koenker and Bassett (1978) 首先提出了分位回归模型的概念。分位回归是一种统计方法,它旨在对条件分位函数进行统计推断。正如基于残差平方和最小化的经典线性回归方法能估计条件均值函数一样,分位回归方法为我们提供了一种估计条件分位函数的机制。一个著名的分位回归的特例就是最小绝对偏差(LAD)估计,它将中位数拟合成协变量的线性函数LAD估计内在的引人入胜之处就在于它在度量位置参数的时候,比均值好。
而后,分位回归取得了长足发展。下面仅仅是几个典型的例子:1.在参数分位回归模型方面, Portnoy and Koenker (1997) 讨论了线性规划中内点问题的最新进展;2.在非参数分位回归模型方面,Yu and Jone (1998) 提出了“双核”(Double-kernel)法;3.在半非参数分位回归模型方面,Koenker,et al .(1992) 给出了一种解决基于罚似然估计(the penalized likelihood estimation)的算法;4.目前,分位回归有几个热门话题:时间序列中的分位回归;分位回归的拟合优度以及贝叶斯分位回归,等等。有关分位回归的优点可以初略地概括如下:1).给定一组预测变量之后,它能全面刻画响应变量的整个条件分布;2).分位回归模型有线性规划代理 (LP),这使得估计简便;3).就像LAD 这一特例一样,分位回归的目标函数是加权的绝对偏差和,所以它能给出一个稳健的位置测度,因此,被估计的系数向量对响应变量的离群点(Outliers)不敏感; 4) 当误差项服从非正态的时候,分位回归估计量要比最小二乘估计量更为有效,等等。
“局部自适应分位回归”(Tian)考虑自适应权重选择的非参数条件分位回归问题,提出了一些理论性质及其应用,并且已经证明了本文提出方法的优良性质,首先不需要模型的先验信息、避免了维数灾难,特别是对于跳跃点和不连续点问题都表现出了很好的性质。我们建立了一个关于局部自适应窗宽的一个自动选择方式。这个算法对于高维情况也适用,同时,我们建立了模拟研究和实证分析,它们都体现出我们这种新方法无论在理论上还是实际中都体现出了优良的统计性质。
“分位回归中的可加模型”(Koenker)介绍了惩罚分位回归,条件分位函数可以有解决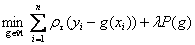 的估计得到,其中 的估计得到,其中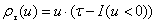 表示检验函数,并且P表示一个惩罚项,它是用来控制拟合函数 表示检验函数,并且P表示一个惩罚项,它是用来控制拟合函数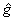 的粗糙性的。 的粗糙性的。
来自Chinese Academy of Sciencess 的Yong Zhou 博士作了题为Efficient Estimation and Inference for Quantile Regression with Varying-Coefficient Models with Censoring的报告。本报告讨论了应用分位回归模型研究带有删失数据的变系数模型问题,构建了一个倒概率删失加权的估计方程。对所提方程使用MM方法进行求解,推导了所提方法的局部Bahadur表达并且证明了估计量的渐近正态性。同时给出了协方差矩阵的相合有效估计。在实际应用中,建议使用重抽样方法进行参数估计,模拟和实际数据都显示了所提方法的优越性。
8、时间序列与混沌
报告“应用广义半参数动态因子的高维非平稳时间序列的建模”(Song Song,柏林洪堡大学,Wolfgang Härdle,加州大学伯克利分校,Ya'acov Ritov,耶路撒冷希伯来大学)对于高维时间序列数据,应用广义半参数动态因子方法可找到高维相依结构并可做高维的分类。
报告“带有缓慢衰减相关性的混沌阵发映射的频率分析”(R.J.Bhansali,利物浦大学和M.P.Holland,萨里大学)给出了一种新的方法来刻画长记忆性,介绍了从代数学角度来定义阵发映射族,很多已知的带有缓慢衰减相关性的阵发映射的例子都可用他们所介绍的定义的理论框架来解释。
9、贝叶斯方法应用研究的新进展
报告“随机化回答求和评分变量的贝叶斯分析”(Jong-Min Kim,明尼苏达大学莫里斯分校)对于两类在自我保护假设下的随机化回答求和评分变量的Poisson回归模型给出了贝叶斯方法,随机化回答的数据来自荷兰2004年关于违反社会保障条例的调查,并就此数据来演示前面所提的模型。
报告“识别记忆和心理学实验中的贝叶斯分层模型”(Dongchu Sun,密苏里大学)回顾了贝叶斯分层模型在三种形式的心理学研究中的最新进展。讨论了MLE的存在性以及贝叶斯分层模型先验值的选取,在实际问题中当似然函数不能很好发挥作用时贝叶斯分析可以取得很好的效果。其中先验值的选取十分关键,至少稳健性是需考虑的。如果可能应选取客观先验值来做个比较。
报告“置信推断与客观贝叶斯推断的比较”(Jan Hannig,北卡罗来纳大学教堂山分校)推广了Fisher的置信方法,给出了适用实际任意情况的置信准则。并用各种复杂的例子来说明这一准则。同时发现了,出于模拟与理论上的考虑,基于这一准则的统计程序的情况表明它们具有好的重抽样频率论的性质。比较了推广的置信分布与相应的客观贝叶斯分布。报告的部分内容基于与Hari Iyer, Thomas C.M. Lee, Jessi Cisewski, Dongchu Sun合作的工作。
“赞同实验政治支持的贝叶斯测量模型并应用于巴基斯坦的激进组织”(Kosuke Imai) 为测量队政治势力(比如候选人、党派以及其他的政治组织)的支持水平以及他们对事物所有权的强度,抽样试验经常被实施。在抽样试验中,响应者被要求表达他们对由随机选取的政治势力所赞同的某特定政策的观点。然后这些响应者和来自被问及没有赞同的政策的控制组进行对比。这种抽样策略在研究敏感政治态度方面是非常有效的。针对这种赞同实验我们发展一种贝叶斯测量模型。我们的模型是基于条款响应理论,并对群体水平和个人水平的政治支持提供估计。这些水平的测量是基于对响应者理想得分的同一尺度进行的。另外,这个模型不仅可以估计对任一给定政策各个政治势力事务所有权的强度,还可以估计出响应者自身特征和他们对某一特定势力支持水平之间关系。最后,我们提供经验和模拟证据来说明该方法的应用性和统计有效性。我们对巴基斯坦最近的一个抽样试验的分析揭示了公众对不同的激进组织的有趣的支持模式。
10、多元统计前沿方法
报告“Copula回归设置中方向依赖性介绍”(Jing Li,明尼苏达大学)讨论了如何证实两变量之间的方向性依赖问题,并给出了在此条件下Copula回归模型的构造方法。报告介绍了Copula方法的发展和变量之间存在方向性依赖的问题,并通过169对夫妻的身高和年龄给出了方向性依赖的实证。报告提出了通过Copulas回归现在组合再截掉不变的Copulas的方法来构造Copulas回归模型,并举例做了说明。Copula理论解决了传统相关性分析方法无法解决方向性的问题,为弥补传统多元统计假设的不足与缺陷提供了一条有效的途径。
报告“利用迭代估计方程对纵向多节点数据建模”着重解决了两个挑战性的问题,分别是响应变量的分布和联合分布问题以及密集计算问题。报告以空气污染中二氧化硫和氮化物的排放为例说明了所要研究的纵向多节点数据的问题。报告从多重端点出发,构造潜变量;同时从协变量出发,构造潜变量与协变量间的结构关系,从而共同完成了纵向多重端点数据的建模工作,通过迭代算法对模型参数做了估计。报告指出估计具有一致性、渐进无偏性和稳健性。
11、统计诊断研究
报告“基于多阶马氏链的序列比较”(Xiang Fang,内布拉斯加林肯大学;Shunpu Zhang,内布拉斯加大学奥马哈分校;Guoqing Lu,美国国家癌症研究院)着眼于生物信息学领域的序列信息比较这个问题。报告首先简单阐述了处理这类问题的两类常用方法,本报告中的方法是在第二类方法中的马氏链方法的基础上发展出来的。报告接下来说明了马氏链方法的原理、它的合理性以及生物信息学中DNA序列的马氏链模型,然后给出了多阶转移阵(MTM)的定义、多阶转移阵中每个转移概率的定阶方法以及用来衡量序列相似程度的距离的计算方法,从而完整的阐述了多阶马氏链方法。报告用多阶马氏链方法处理了流感病毒数据并且给出了结果,结果说明了这种方法的优势,在此基础上得出了结论,肯定了多阶马氏链方法在处理序列信息比较的问题时的先进性并且预测了这种方法未来可能会改进的地方。
报告“灵活的逐步回归:多变点检测的一种自适应分割方法”(Yinglei Lai,乔治华盛顿大学)处理的是“时间进程”数据,“时间进程”是连续或者定序的预测变量,数据的相应变量可以是连续的或者二值的。最优化算法和传统的动态规划算法都不能达到建立模型并进行预测的目标,改进的动态规划算法则满足了要求。报告接下来给出了改进的动态规划算法的具体内容,这种方法得到的估计量具有相合性,然后给出了这个回归模型的检验统计量以及响应变量值的置信区间,并且把这种算法推广到了响应变量是二值变量的情况。把改进的动态规划算法与广泛应用的递归分割方法和递归组合方法进行了对比,总结了改进的动态规划算法的优点和缺点。
报告“主成分分析法何时能得到较满意的结果?”(广东商学院,林海明)针对主成分分析法得到较满意结果的问题,应用变量与主成分的相关阵与因子分析主成分法估计的因子载荷阵的关系和比较,明确了:主成分分析法何时能得到较满意结果的一个条件,主成分个数确定、主成分命名更好的依据和检验等。报告给出了主成分分析法用于综合评价的一个推荐步骤,列举了国际女子径赛项目数据的综合评价实例,发现其结果具有相应的决策相关性等,进一步给出了主成分分析应用时的一些建议。
报告“局部影响分析及其应用”(云南财经大学,石磊)则主要是方法介绍。报告先对局部影响的方法进行了介绍,包括约束的影响分析和逐步局部影响方法两部分,然后分别介绍了其在线形回归模型、线形混合模型和实践序列ARIMA模型中的应用。
四、生物医学统计
1、基因、DNA和蛋白质数据的统计分析
Michael S. Waterman博士(University of Southern California)作了题为Eulerian Graphs and Reading DNA Sequences 的主题发言。该发言首先介绍了DNA序列分析的历史,接着讨论了有关DNA序列拼接研究进展与挑战。之后着重探讨了新时期的DNA序列研究特点以及应用欧拉图方法对DNA序列进行分析的优势与难点。
Hongyu Zhao博士(Yale University)作了题为 Weighted Random Subspace Method for High Dimensional Data Classification的报告。该报告指出来自基因和蛋白质研究的高维数据,因其数据维度大并且常常带有噪声,给传统的分类算法带来了极大的挑战。变量预筛选与组合算法等方法可以解决这个问题,但是通常变量筛选方法没有考虑变量之间的交互作用并且容易过拟合数据。组合算法(bagging, boosting, 随机子空间方法,随机森林方法)处理高维数据较有效,但是缺乏对该方法最优权重分配的讨论,这妨碍了组合算法得到更精确地分类结果。本报告给出了一个探索式的最优权重分配方法,并将其应用到随机子空间方法,得到加权随机子空间方法。该方法用来分析公开的基因表达数据以及质谱数据,相对于等权重方法,所提方法有显著提高。
Yazhou Wu博士(Third Military Medical University)作了题为 Methods of Gene Regulatory Network Model for Expression Data of Temporal Gene的报告。基因调控网络是功能基因组学的重要内容,也是生物信息学研究的前沿问题。一个备受关注的问题是如何在海量的基因表达数据中分析互补基因的调控关系。通过对人脑三个区域基因芯片数据的处理和分析,该报告比较分析了微分方程模型、Lotka-Volterra模型、关联规则等现有模型。在此基础上提出整数非线性规划模型。该模型在权重选择方面更客观合理,并且得到更好的数据分析结果。该模型为分析基因表达数据以及生物信息学的研究提出了新的方向。
Zehua Chen博士(National University of Singapore)作了题为 A Two-stage Penalized Logistic Regression Approach to Case-control Genome-wide Association Studies的报告。本报告讨论了使用两阶段带惩罚Logistic回归方法进行全基因组关联研究。在第一阶段,使用L1惩罚的似然函数选择变量的主效应和交互效应,在第二阶段,使用带SCAD和Jeferry’s Prior惩罚的似然函数对保留下来的变量进行排序,拟合一系列嵌套模型,并使用扩展的BIC准则对模型进行评价。在大样本条件下,模型有很好的渐近性质。通过模型研究了模型在有限样本下的表现。并且与现有方法进行比较,分析了CGEMS前列腺癌数据。
郭建华博士(东北师范大学)作了题为 Genome-Wide Association Studies Using Haplotype Clustering with A New Haplotype Similarity的报告。基因的关联分析对研究与基因有关的疾病非常重要,在所有的分析方法中,基于单倍体的关联分析有很多优点,但也受限于单倍体很少的事实。单倍体聚类提供了一个解决放案。本报告提出了一个基于新的相似度的聚类方法。模拟数据表明该方法可以很好的发现疾病标志物的关联。该方法应用到实际数据分析,得到了高精度的估计。
Yu Zhang博士(Penn State University)作了题为 Fast and Accurate False Positive Control in Genome-wide Association Studies的报告。全基因组关联分析通常涉及到对成百万的SNP进行测试,因为SNP之间的连锁不平衡使得基于SNP的关联测试具有高度的相关。简单的Bonferroni修正和排列检验都不能很好的解决该问题。本报告提出一个新方法,即易于计算又可以得到很高的准确性。理论证明新方法的准确性以及计算所需时间与样本量、SNP数量和p值无关。应用到实际数据分析发现不同基因区域差别很大的保守性,这与SNP的连锁不平衡和密度有很大相关。新方法可以进一步被用来控制错误发现率。
“罕见变异全基因组测序研究的association分析统计方法”(Xihong Lin)提到高通量测序技术正迅速成为基因组研究的可行方法。例如,用于定义与疾病相关的罕见变异。然而这些数据的分析具有很大的挑战。例如对于有限样品,因果变量可能不能分析出来,因为他们很少见而且多个变种可能具有因果关系。我们开发了加权核机器方法用于分析全基因组关联研究的测序数据。我们证明我们的方法较其他现有的方法强大。
“Generalized genetic association study with samples of related individuals”(Zeny Feng ,Department of Mathematics and Statistics,University of Guelph)介绍到Genetic association studies 是发现与人们所感兴趣的一些复杂特征相关的遗传因子的一个必不可少的步骤。在此报告中,介绍了一个新颖的广义拟似然评分测试,此方法既适用于量化的特征又适用于二分类性状的association study。作者应用了一个logistic 回归模型将所感兴趣特征的临床测量和等位基因频率的分布相联系。模拟结果显示此方法比family-based association test (FBAT) 更有强大并能控制第一类错误在所要求的水平。作者还应用此方法分析了实际的数据,得到了新的与所感兴趣的复杂特征相关的显著SNP。
2、生物网络研究
“基因表达的数量性状座位数据的网络分析”(Hongzhe Li,美国宾夕法尼亚大学)介绍到现在的遗传基因组学试验常规性的要测量遗传变异体和基因表达数据。而基因表达的水平往往被看作是数量性状,而且为了确认基因表达的数量性状座位要用标准的基因分析方法。但是很多基因表达的架构是很复杂的,如果对基因表达的架构估计不好则会造成在转录水平对基因依附结构的估计不良。Hongzhe Li介绍了几种分析基因表达的数量性状座位数据的方法,包括对推导基因效果和基因关联网络的稀疏相依回归模型和对动态共表达分析的惩罚似然估计法。
“对加权遗传交互网络的模块分析”(Minghua Deng,北京大学)高通量基因遗传学相互作用图谱方法(EMAP)可以画出大型的基因相互作用的网络,但复杂的分析这种网络的计算方法仍有待发展。为了解决这个问题,Minghua Deng采用了混合程序建模来构建一个加权遗传交互网络,然后运用一个概率体制来确定网络中的密度交互模块。混合程序模型是EMAP里的软阈值技术。他还用他们的方法对一个早期分泌性途径的EMAP数据集进行了预测,共预测有254个模块。在这些模块中,有88个可以在基因本体中找到,7个可以在京都基因与基因组百科全书中找到,6个可以在慕尼黑蛋白质序列信息中心找到。
“对给定流行病学数据接触网络的贝叶斯推断”(David Hunter,美国宾州州立大学)网络现在很普遍的用于流行病学的研究中,不同的接触网络结构会导致不同的流行病学动力学。但是目前关于对给定的流行病学数据潜在网络结构的推断的研究还很少。David Hunter的研究是在Britton和O’Neill工作的基础上,他们俩提出了贝叶斯框架来估计参数,包括接触网络的参数。David Hunter的研究是对感染宿主复原时间的简单随机网络的分析。他介绍了两个对基本模型的扩展模型:第一个模型,他扩展了易感-暴露-感染-复原的流行病学模型,使得模型能符合有指数型传播时间、Gamma型分布的潜伏期和感染期的某类疾病。第二个模型,他认为指数族随机图模型比Erdos-Renyi网络模型更完善。他的这些模型都可以用R软件来实现。
“动态网络分析:模型、算法、理论和应用”(Eric Xing,美国卡耐基-梅隆大学)社会的结构和组织以及它的不断变化是一个拓扑重联以及语义随着时间或是随着世代不断进化的随机网络。有大量的关于这种定常网络的文献,但是目前为止对这种拓扑重联网络的动态过程的模型研究还很少。Eric Xing介绍了两种近来新发展的分析动态层析进化网络的方法。第一种是新的稀疏编码算法,用来估计有着非稳定性时间序列或是有着节点分布的树序列的隐匿性进化网络的拓扑结构。第二种是新的贝叶斯模型,用来估计和可视化进化网络节点结构多功能的轨线。最后Eric Xing还展示了一些实际的例子,如美国参议院和安然公司的进化社会网络的例子和年老果蝇的进化基因网络的例子。
“人类近代的祖先”(Joseph Chang,美国耶鲁大学)研究考虑的是所有人类共同祖先模型的概率问题。他的研究主要聚焦在家谱网络上。在一个随机婚配的人群里,最近的共同祖先可能生活在非常近的过去,人口的数量是呈对数性增长的。但是随机婚配模型忽略了人群里的亚结构,比如有些人只和同一社会阶层的人进行婚配,还有一些地理上相对孤立的人群。因此寻找人类共同祖先可能需要某种考虑了人群亚结构的模型,而且人类的谱系在过去可能有着某种重叠。在这些模型中,人类最近的共同祖先可能就存在于几千年前,而且当今的人类有着共同的祖先。
此外,来自美国哈佛大学的Edo Airoldi,也以“网络统计和网络中的进程”为题做了精彩的演讲。
3、统计在神经影像学中的应用
“函数型数据的分析、因果推断和脑连接”(Martin Lindquist,美国哥伦比亚大学)函数型数据的分析和因果推断是近来统计界很感兴趣的两个问题。但是,在神经影像学里这两个问题的研究和应用还很少。Martin Lindquist介绍了一些函数型数据的分析和因果推断在神经影像学里应用的例子。最后他还介绍了一个用函数通径分析模型来研究脑连接的例子,并且用因果推断的方法对函数通径分析的结果估计了平均的因果效能。
“对有色信号的独立成分分析以及在功能性核磁共振成像中的应用”(Young Truong,北卡罗来纳大学教堂山分校)功能性核磁共振成像和结构性的核磁共振成像很类似,简单来说功能性核磁共振成像就是快速、不断重复的结构性核磁共振成像。它对脑活动的改变十分敏感,而脑活动增加了血氧的含量,在图上表现为测量信号的增强。因此功能性核磁共振成像可以说是依靠于血氧水平的。
“对结构和功能性脑影像的统计学分析”(Y. Michelle Wang,伊利诺伊大学厄本那—香槟分校)因为在脑医学中的一些关键性问题,所以发展能够准确有效的分析大量脑影像的统计方法就显得非常重要。但是影像采集参数的不确定性,人体解剖和生理上的变异以及影像数据本身的噪音、相关性等等,这些因素都会引起计算问题。Y. Michelle Wang在演讲中介绍了他们针对脑部的形态计量、神经电路以及在结构和功能性核磁共振成像中个体差异问题而发展的一些统计学方法。最后她还介绍了用这些方法对模拟数据和实际影像数据分析的结果。
“利用统计方法估计磁脑照相术(Magnetoencephalography)信号源的个数”(Zhigang Yao,美国匹兹堡大学统计系)指出,MEG是一种图像处理分析技术,处理对象是人脑所产生的电磁信号,以实现对人脑功能的研究。由于MEG数据的高维度特点,所以其中的主要问题是信号源个数的确定。目前现有的信号源估计方法主要包括主成分分析法、因子分析法以及AIC法等。然而上述方法在实际信号个数与噪声信号个数的比值较小的情况下会很敏感。由于实际应用中噪声是未知的,因此噪声估计就至关重要。报告采用小波方法,傅立叶方法和残差估计方法估计噪声,并进行了统计模拟和各种方法的对比研究,结果表明较现有的传统方法,小波方法和傅立叶方法等更适合于MEG高维数据的研究。
4、自适应设计和临床试验
“对协变量自适应随机化下的研究假设验证的理论研究”(Jun Shao,威斯康星大学麦迪逊分校)指出协变量自适应随机化方法已经提出很长一段时间了,但是与它相关的统计推断的理论研究还很少。在实际应用中,很多人就采用适合简单随机化的推断方法,但其实这种方法在其他随机化里并不适用的。他展示了一种获得有效性验证的方法,就是用结果变量和协方差之间修正性的模型。他还展示了简单的两样本的t检验的结果,考虑到I型误差,这个结果在协变量自适应的有偏硬币随机化下是保守的。在这里可以构建一个bootstrap的t检验方法。他最后还展示了这几种检验在理论和实际数据中的检验效度。
“自适应随机临床试验的总结与展望”(Feifang Hu,美国弗吉尼亚大学)指出自适应随机临床试验是在过去10年非常热门的一种研究方法,Feifang Hu在演讲中介绍了在临床试验中什么时候需要使用自适应随机化的方法,如何设计一个好的自适应随机化的临床试验,以及如何进行统计推断。最后,他还介绍了自适应随机化临床试验未来可能的发展方向。
此外,来自美国华盛顿大学Xiao-Hua Andrew Zhou,以“在选择最优化诊疗里对生物标记物的预测准确度进行评价”为题做了精彩的演讲。
5、生存分析模型的前沿研究
“复发性分析:长度-频率权衡”(Jason Fine,威斯康星大学麦迪逊分校统计学院生物统计与医学信息系)共分为六个部分,第一部分对比介绍经常性事件与反复性发作;第二部分对rhDNase数据:数据分析中所遇问题进行分析;第三部分探讨目前的解法方法;第四部分介绍时空过程回归方法;第五部分是对rhDNase数据的再分析;第六部分总结。
“利用超高维变量对cox模型的原则确定独立性筛选”(Dana – Farber & Dave Zhao,哈佛大学公共卫生学院)报告第一部分介绍“多发性骨髓瘤”,其症状表现为骨病变,免疫系统失调,肾功能衰竭,在确诊后患者存活率仅为10%。目标是“靶向治疗”,也就是要达到有针对性的治疗效果。第二部分报告多发性骨髓瘤“靶向治疗”的探寻过程。第三部分报告SIS:确定独立性筛选。第四部分详细报告PSIS算法。第五部分报告为多发性骨髓瘤寻找替代基因的过程。
“带信息区间删失下生存数据的线性风险模型”(孙建国等,密苏里大学统计学院)报告共包括四个部分及一个附录,报告第一部分主要是举例介绍两类区间删失数据及文献回顾。报告的第二部分是关于带信息删失的线性风险模型的推导。报告的第三部分是乳癌研究的分析。报告的第四部分是结论讨论部分,作者先是介绍了这个方法的局限性,并提出可以将这个方法一般化推广到K个区间删失数据,同时提到了未来可以研究的方向。在报告的附录部分,作者介绍了生存分析回归模型中最通用的比例风险模型。
来自Fred Hutch 的Megan Othus博士作了题为 Marginalized Frailty Models for Multivariate Survival Data的报告。本报告讨论了多元生存分析中的高斯copula模型,开发了一个可以用于研究分类的生存分析数据的模型,并且可以检验各类之间的相关是否为零。模型的参数可以使用现有软件进行两步估计。应用该模型很好的拟合了儿童急性成淋巴细胞性白血病的数据。
6、医疗与卫生保健统计方法研究
Bojuan Zhao博士(天津财经大学)作了题为 Longitudinal Modeling of Age-specific Mortality的报告。对于短期的死亡率数据,著名的Lee-Carter模型很难给出稳定的特定年龄的死亡率预测,本报告使用三次样条及其他可加函数改进Lee-Carter模型解决这个问题。所提模型在稀疏数据的情况下,可以给出光滑平稳的期望死亡率估计。该模型用来估计中国2000-2008年分年龄分性别的死亡率数据,拟合效果优于Lee-Carter模型。本报告所提模型对分析其他纵向数据(比如生育率数据)同样具有很高的价值。
来自University of Hong Kong的Joseph Wu博士作了题为 A Serial Cross-sectional Serologic Survey of 2009 Pandemic (H1N1) in Hong Kong: Implications for Future Pandemic Influenza Surveillance的报告。在全球性流行性感冒发作的初期,公共卫生管理的一个紧急的首要的任务是估计它的传播性和严重性,这是很困难的事情,因为很多流感症状临床并不显著。人群的血清监测可以有效的估计病毒感染率,结合临床的住院和死亡数据,可以准确的估计新病毒的严重程度。2009年流感爆发期间,本报告在香港进行了一个详细的血清监测研究,基于对15000个捐赠者,1000社区患者以及4000个门诊病人的血清样本的分析,我们估计出基本复制数字为1.35,住院率随年龄段0-12到60-79为U型分布。第一波段之前之后的血清数据即可以用来估计病毒的感染率和严重性。使用计算机模拟计算为了准确估计病毒传染性和严重程度而每天需要监测的样本量。
五、其他统计前沿研究
1、机器学习理论与应用研究最新进展
围绕“机器学习理论与应用发展”的分会会议主题,分别从机器学习应用、理论与非参数统计与其他学科之间的关系等角度进行了分类总结,学术报告可归纳为“机器学习应用的数据基础”和“机器学习的统计学机制”两个大的基础理论问题,而解决问题的途径必须在方法·数据耦合系统的大框架下进行探索。
(1)微观数据算法设计引领机器学习应用前沿
信息技术的飞速发展推动了微观数据采集技术在测量广度和深度上的飞速发展,广袤的微观数据世界吸引了众多统计学家的视线,为基于微观数据的统计机器学习设计开辟了巨大的研究空间。本次会议关注的热点微观数据领域包括分子生物学、金融学、信息技术学等领域,很多精彩的报告都给出了来自于领域的算法设计的新思考和新思想。比如,在网络链接数据上,微观数据算法设计正在引领机器学习应用前沿。
朱冀教授的学术报告“网络社区发现”算法设计中考虑了网络聚类问题,研究中考虑了与传统切割法不同的随机游走方法,设计允许大量背景信息与有效聚类信息共存情况下的链接数据聚类,探讨了新聚类算法的效率和稳定性问题。
此外,马志明院士的特邀报告也体现了对该领域发展的重要贡献(参见前面的详细内容)。虽然有很多学者对Pagerank算法改进以优化计算速度,很少有学者研究不同的数据对综合评价算法的影响。马院士提出的BrowseRank将用户在网页上的使用信息有效地加入到算法设计中,以实现网页的民意排序是一项新发展的应用研究。
(2)非参数估计与机器学习成果丰富
在非参数理论分会上,Lu Tian考虑了得分函数估计问题,提出使用重抽样方法估计非线性交互作用函数,在此基础上采用二阶选择函数,指出在一定假设条件下,添加变量可用于估计效率的提高;Tyler J.VanderWeele给出基因基因和基因环境交互作用条件下的因果推断问题的解,提出使用自然直接因果效应和自然间接效应对交互效应分解,使用非线性模型构造优势比给出问题的估计模型,并用肺癌病的实验数据通过实证研究说明该方法在估计中的适用性。Xiaohong Chen将PSMD置入式估计用于半参数或非参数条件和非条件矩模型中,使该方法扩展至矩估计中,考虑了估计的正态一致性估计问题,建立了基函数的根号n估计理论,给出了估计的卡方近似检验分布。
在非参数应用分会场上,李银国等考虑了面板数据的聚类算法设计问题,讨论了面板数据聚类距离的三种传统定义方法,考虑了加权权重设计问题,提出加权聚类距离设计,使用实际数据给出不同距离设计下的结果比较研究。谢尚宇等考虑了存在条件极端事件误差的非参数回归中的非参数估计问题,对尖峰探查方面的研究提供了全面概述和总结,提出了一种基于小波设计的可用于跳跃和尖峰探查和估计方法。
在机器学习理论分会场中,Jinchi Lv考虑了NP维即超高维下的非凸罚似然估计问题,讨论了一般信息准则BIC、SIC在几种重要的凸惩罚函数中的性质及其在惩罚似然模型选择中的稀疏性和连续性表现,指出凸惩罚函数在变量选择中普遍具有约束性不强的特点。作者提出ICA算法给出爬升解路径保证惩罚似然函数对固定的调节系数产生增长序列从而得到合理的似然估计。Rui Song考虑了超高维稀疏可加模型的非参数独立滤网问题,提出可加模型变量选择的NIS算法,给出可用于正率误差减少的INIS算法,实证研究表明了算法的有效性。
现代统计学的发展突破了传统统计学的数学界限,在多维视野和多个空间尺度连接过去、现在和未来,耦合着自然界、人类社会和经济的运行。中国统计学的迅速发展是今日和明天信息环境和的需要,对于实现知识经济发展也具有举足轻重的意义。过去二十年间,我国统计学科学虽然取得了长足进步,但离国际统计学先进水平尚存较大差距,加强国际学术交流是缩小差距的有效途径。通过本次会议,国内外优秀统计学家给我们们带来了一些学科发展的前沿和理念。责任成就事业,有为才能有位。借国际论坛统计盛事,我们一方面应深入挖掘机器学习与传统概率数理统计的综合理论研究,另一方面积极围绕国家重大需求创造性地开展统计机器学习的应用,使统计机器学习在中国的这片土壤上硕果累累。
2、图像统计研究
“数据云的分析:图象分类的层级高斯化”(Feng Liang,University of Illinois at Urbana-Champaign统计系)首先说明了数据云的概念,在图象分类/回归中,每个样本不是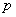 维空间中的一个点,而是具有形式 维空间中的一个点,而是具有形式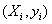 ,其中 ,其中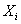 是一个 是一个 矩阵,该矩阵各列的维向量不分次序。然后为了解决图象分类所需要的输入问题,将图象表示法所需的建模参数分为三个层级:类别级、图象级和patch级。在此基础上,给图象的高斯化数据建立了贝叶斯层级模型,并给出了三个层级模型的实用估计方法。基于这种思路的分类法在分析常见的数据集PASCAL VOC 2007和PASCAL VOC 2009中明显优于现有其他分类方法。 矩阵,该矩阵各列的维向量不分次序。然后为了解决图象分类所需要的输入问题,将图象表示法所需的建模参数分为三个层级:类别级、图象级和patch级。在此基础上,给图象的高斯化数据建立了贝叶斯层级模型,并给出了三个层级模型的实用估计方法。基于这种思路的分类法在分析常见的数据集PASCAL VOC 2007和PASCAL VOC 2009中明显优于现有其他分类方法。
在随机理论与图像模型分会场中,“协方差矩阵下的共轭分布”(Helene Massam加拿大约克大学)介绍了从1993年到2010年之间关于协方差矩阵的共轭先验分布的发展过程,重点介绍了其中的六篇文章:Dawid and Lauritzen (1993),Brown, Le and Zidek (1994),Consonni and Veronese (2003),Sun and Sun (2005),Letac and Massam (2007),Khare and Rajaratnam (2010),并进行了比较说明。DL(93)主要针对关于可分解图像的图像高斯模型的马尔科夫做了一定的工作,并且给出了马尔科夫和马尔科夫分布的定义。给出了协方差矩阵的DY共轭先验分布,其密度为HIW;BLZ(94)利用倒序和IW分解的方法来建立一种新的先验,而不是DY共轭先验;CV(03)处理由实数、复数或四元数构成正定矩阵的锥,利用条件自然指数族(NEF)和丰富的标准先验分布的相关族的理论推断出先验分布的共轭性,建立具有参考价值的先验,非DY共轭先验;Sun and Sun (05)考虑了关于星状图形的高斯模型的马氏的协方差矩阵估计问题;LM (2007)通过给出不同的形状参数对HIW进行了扩展,并且也说明也具有直接的超马氏性质;KR(2010)对共轭先验分布做了进一步的扩充。
3、设计与过程控制
“基于变量选择的多变量统计过程监视与诊断MEWMA控制图的开发”(清华大学工业工程系 王凯波,香港科技大学 Wei Jiang Fugee Tsung)多元指数加权移动平均MEWMA控制图是最有应用价值的多元控制图之一,然而,当MEWMA图发出失控信号时,很难说明哪个变量或哪些变量处于失控状态。报告介绍了变量维数与中心漂移发现概率的关系,强调过程监视和错误诊断是同等重要的, 提出的基于变量选择的VS-MEWMA控制图,把监视和诊断集成在同一个步骤中,发出报警时,可以有效地确定那些失控的漂移变量。
“计算机仿真试验的套格子点样本”(艾明要,北京大学数学科学院概率统计系)计算机仿真试验称为充满空间的设计,在试验范围内选出均匀散布的试验点,其两种主要方法是拉丁超立方体抽样和均匀设计,报告介绍的套格子点样本方法属于拉丁超立方体抽样。报告首先回顾了拉丁超立方体设计的发展过程,介绍了套置换等有关概念。在此基础论述了套格子点样本方法,用一个示例给出图形展示,介绍了该样本的几种具体构造方法,有Rao-Hamming方法、差分矩阵方法、Bush方法等,以及该方法的优良性质。最后提出了该方法的几个需要进一步研究的问题。
“分式因子设计的GMC理论”(张润楚,南开大学数学科学学院 东北师范大学数学与统计学院)研究了二水平因子的正规设计问题,在正规因子设计中,字长用来刻划一个因子设计有关主效应和交互效用的混杂情形,两个重要的准则“最大分辨力”和“最小低阶混杂”都是字长的函数。作者指出现有准则的缺陷,例如找不到最优设计方案,提出了能够有效找出最优设计方案的一般最小低阶混杂GMC准则,该准则基于对设计方案的AENP分类,AENP分类是作者与合作者在2008年提出的根据混杂效应数目对试验设计方案的分类方式。
4、实验设计
“最小最大实验设计”(Nyquist) 先定义设计问题,研究的模型是:相应变量Y服从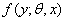 分布, 分布,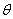 是未知参数向量,x是设计变量向量,例如简单线性回归 是未知参数向量,x是设计变量向量,例如简单线性回归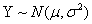 ,其中 ,其中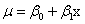 ,Logit模型 ,Logit模型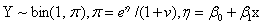 ,多元正态响应变量形式 ,多元正态响应变量形式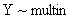 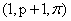 ,Y和 ,Y和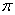 是p元向量, 是p元向量,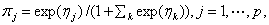 ,并且有 ,并且有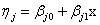 ,二项分布 ,二项分布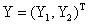 , ,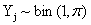 并且独立。 并且独立。
“建立两类的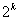 和 和 设计” Liau 讨论了带两水平的的因子设计,举例来说,如果我们有双胞胎或一双鞋、一双袜子、一双眼睛或者只有两个可用的机器。将因子命名为1,2,3,...,k,如果我们想估计所有的效应并且估计所有和两因子的交叉效应,那么需要多少个组呢?其中Draper and Guttman (1997) 给出了 设计” Liau 讨论了带两水平的的因子设计,举例来说,如果我们有双胞胎或一双鞋、一双袜子、一双眼睛或者只有两个可用的机器。将因子命名为1,2,3,...,k,如果我们想估计所有的效应并且估计所有和两因子的交叉效应,那么需要多少个组呢?其中Draper and Guttman (1997) 给出了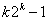 个组,Kerr (2006) 提出了 个组,Kerr (2006) 提出了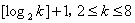 个组,Yang and Draper (2003) 探讨了k = 2, 3, 4, 5的情况,Box and Hunter (1981), Daniel (1962), John (1971), Montgomery and Runger (1996), John (2000), Wu and Hadama (2000) 提出了折叠法设计的特定因子。 个组,Yang and Draper (2003) 探讨了k = 2, 3, 4, 5的情况,Box and Hunter (1981), Daniel (1962), John (1971), Montgomery and Runger (1996), John (2000), Wu and Hadama (2000) 提出了折叠法设计的特定因子。
5、稀疏推断研究
在稀疏推断分会场中,“识别分层网络结构中稀疏点的方法”(Aarti Singh,卡内基梅隆大学)研究了如何在网络中发现活动信号比较弱的点,比如神经网络中神经元的微弱变化、河水被污染的迹象等。报告首先介绍了分层的方法:最小组内相似性大于最大组内相似性,其中相似性用协方差度量;然后将网络活动分为分层独立结构已知和未知两种情况。在网络点的独立结构已知的情况下通过对测度的正交变换提高网络点的稀疏性从而放大弱信号点,再对弱信号点进行假设检验以判断其是否属于活动区域的点。如果网络点的独立结构未知,通过之前网络活动学习其分层独立结构,然后同第一种情况。报告证明了正交变化以放大弱信号点的有效性并通过实证分析验证了方法的可行性。
6、统计方法在气候研究中的应用
Shi Tao博士(俄亥俄大学统计系)的报告主题是“AIRS第3级量化数据的统计分析”(Statistical Analysis of AIRS Level 3 Quantization Data)。AIRS 是Atmospheric Infrared Sounder的缩写,包含三级逐级汇总的数据。第1级数据是实际观测到的空气、地表温度、水汽和云层特征,观测的时候将地球划分为45公里边长的“足印”(footprint);第2级数据将每个足印上的观测数据转化为一个35维向量,数据量为每个月2..72G;第3级数据按照5度×5度的尺度用多维直方图汇总每个月的第2级数据。本文采用Mallow距离,建立了分布之间的距离,进而为直方图直接建模,所采用的方法参考了虚拟局部映射法(Hypothetical Local Mapping, Li and Wang 2008)。作者认为Mallow距离和均值距离之间存在比较明显的差异,而直方图建模能够反映比前两阶矩更多的信息,所得到的拟合模型可以用来研究局部地区的气候,为数据缺失地区做预测,并和气候模型的输出进行比较。
7、统计教育
“MATLAB辅助的基于积分的商务数学教学方法”(William S. Pan)通过若干实例,生动地演示了如何用MATLAB软件绘制函数的图形、求导数以及计算积分,从而解决实际问题。这种计算机辅助教学方式为信息时代的基础统计教育带来了很多有益的启发。王忠玉,赵正权强调了经济计量学教学方法研究的重要性。
统计国际论坛上专门设置了“应用统计专业硕士”研讨分会场,劳伦斯D. 布朗(Lawrence D. Brown,美国科学院院士,宾夕法尼亚大学统计学教授)专门介绍了美国应用统计硕士的发展现状,应用统计方向包括在管理、经济、金融、生物医学、政府及公共服务、社会等领域有广泛的应用领域。袁卫教授全面讨论了我国应用统计专业硕士的有关问题。他首先比较了科研型统计学硕士与应用统计专业硕士在统计知识体系上的差别,统计学硕士的统计知识体系是统计理论、统计方法和应用研究,应用统计专业硕士在统计方法上与统计学硕士有交叉,但不同的是着重应用统计的方法,在统计应用研究上,应用统计专业硕士更加突出实际技能素质和解决是问题能力上的统计应用知识,此外,应用统计专业硕士还包括统计职业培训的内容,即具有良好的统计职业素质。在课程教学方面,袁卫教授强调基本技能北欧扩调查组织与实施、数据整理与分析(描述、推断方法及应用)、数据分析软件技能(SPSS、SAS、JMP等),以及团队合作能力的培养,案例与实践是核心。做好我国应用统计专业硕士的培养工作,必须要从科研型统计学硕士进行比较大的转型,包括培养目标、培养方案、培养过程、师资结构等做出全面科学的调整,未来发展趋势的硕士培养主体结构应该是应用统计硕士逐渐替代统计学硕士,成为我国高级统计专门人才的主要培养发展目标。上海财经大学统计与管理学院院长艾春荣教授,根据上海地区人才需求现状分析、国际参照系的培养方案,以及上海财经大学的优弱势,提出应用统计专业硕士重点设立四个方向:经济管理统计(针对政府统计部门)、应用数理统计(针对工业界,制药)、数量金融(针对基金)、风险管理(针对银行, 保险, 基金)的发展设想,在专业硕士培养课程方面提出降低理论训练(概率、数理统计合二为一),保留统计方法课程,加大计算机训练,增加写作、案例教学,专业方向课程。调整后的应用统计专业硕士大纲:所有方向必须有下列统计课程:概率论与数理统计、应用回归分析、应用时间序列、计算机语言。其中各个方向的课程分别是:(1)数量金融: 随机过程及其应用,股票,期货与期权理论、金融统计,固定收益与金融工具,投资学。(2)风险管理:流动性风险、信用风险、市场风险、投资组合管理。(3)应用数理统计:数据挖掘,生存分析、案例分析、统计报告写作。(4)经济统计: 国民经济核算、抽样调查、案例分析,统计报告写作。未来实施过程中的困难、挑战主要包括:(1)硬件支持:统计教学实验室、高速模拟实验室。(2)案例库。(3)缺乏有相关方向实际工作经验的师资(4)缺乏方向师资(数量金融、风险管理方向只有5位海外轨)。从应急出发,应该关注引进海外经验丰富的优秀专门人才,解决发展的瓶颈问题。崔恒建教授也针对应用统计专业硕士的培养目标和课程体系等做出了系统的讨论,比较突出的是强调统计应用的各个领域都需要认真开发和建设,培养内容要突出方法的实际应用。国家统计局教育中心邱京南副主任,联系长期以来国家统计系统人才需求和职业资格考试,对应用统计专业硕士的建设与发展,提出了殷切的希望,鼓励大学与实际统计部门积极合作,把职业资格考试与专业硕士有机结合,走出与众不同的专业硕士培养模式。
(综述主要作者:中国人民大学统计学院、教育部应用统计科学研究中心的赵彦云、李静萍、田茂再、张波、王星、金勇进、王晓军、孟生旺、吕晓玲、彭非、王瑜、许王莉、杜子芳、刘文卿、金阳、张景肖、薛薇、黄向阳,最后由赵彦云综合修改定稿。)
|
